Pandas anti-unión
- Pandas Anti-Join y sus tipos
- Realizar el Anti-Join Izquierdo en Pandas
- Realice el Anti-Join Correcto en Pandas

Este tutorial describe las anti-uniones de Pandas, describe brevemente sus tipos y demuestra cada uno usando códigos de ejemplo.
Pandas Anti-Join y sus tipos
Al usar anti-join, podemos devolver todas las filas (también conocidas como registros y documentos) en un conjunto de datos que no encuentran el valor coincidente en el otro conjunto de datos. Estos se utilizan para manipular conjuntos de datos según los requisitos del proyecto.
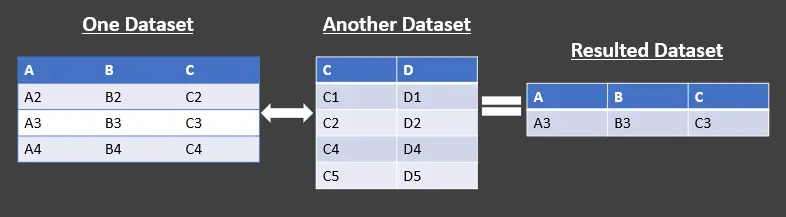
Hay dos tipos de anti-uniones en Pandas que se enumeran a continuación:
- Left Anti-Join: devuelve los registros en el conjunto de datos de la izquierda que no tienen registros coincidentes en el conjunto de datos de la derecha.
- Right Anti-Join: devuelve los registros del conjunto de datos derecho que no coincidieron con los del conjunto de datos izquierdo.
Consulte la representación tabular anterior. Estamos usando el anti-join izquierdo, que devuelve el conjunto de datos izquierdo, excluyendo la intersección.
Tenga en cuenta que solo devuelve columnas del conjunto de datos izquierdo y no del derecho.
De manera similar, el uso de la antiunión correcta devolverá el conjunto de datos correcto, excluyendo la intersección. Al igual que la combinación izquierda, también devolverá columnas del conjunto de datos derecho únicamente y no del izquierdo.
Aprendamos cómo podemos usar ambas anti-uniones en Pandas. Tenga en cuenta que debe tener suficiente conocimiento de combinaciones SQL para comprender firmemente las anticombinaciones.
Realizar el Anti-Join Izquierdo en Pandas
-
Importar la biblioteca.
import pandas as pdPrimero, importamos la biblioteca
pandaspara jugar con marcos de datos. -
Cree dos marcos de datos.
# first DataFrame df1 = pd.DataFrame( {"sections": ["A", "B", "C", "D", "E"], "points": [19, 23, 20, 15, 31]} ) print("First DataFrame:") print(df1) # second DataFrame df2 = pd.DataFrame( {"sections": ["A", "B", "C", "F", "G"], "points": [19, 23, 20, 24, 30]} ) print("\n\nSecond DataFrame:") print(df2)Creamos dos marcos de datos que contienen
puntosde muestra para diferentesseccionesque puede ver a continuación.PRODUCCIÓN:
First DataFrame: sections points 0 A 19 1 B 23 2 C 20 3 D 15 4 E 31 Second DataFrame: sections points 0 A 19 1 B 23 2 C 20 3 F 24 4 G 30 -
Realice la unión externa.
outer_join = df1.merge(df2, how="outer", indicator=True) print(outer_join)Para realizar la antiunión, debemos pasar por la unión externa, que devuelve los valores coincidentes y no coincidentes de uno o ambos conjuntos de datos. Estamos obteniendo valores coincidentes y no coincidentes de ambos conjuntos de datos (puede ver esto en el siguiente resultado).
Aquí, el método
merge()se utiliza para actualizar los datos de dos marcos de datos mediante el uso de métodos particulares para fusionarlos. Estamos usando algunos parámetros para controlar qué valores reemplazar y qué mantener.df2- Es otro marco de datos con el que fusionarse.cómo- Especifica cómo fusionar. Es un parámetro opcional cuyos valores pueden serizquierda,derecha,exterior,interiorocruz; por defecto, esinterior.indicador- Se puede configurar comoTrue,Falseo un valor de tipo cadena. Si lo configuramos enTrue, agregará la columna_mergeal marco de datos de salida que tiene la información en una fuente de cada fila.
También podemos dar un nombre diferente a la columna
_mergeespecificando un argumento de cadena. Esta columna contendrá los valores de tipo categórico, por ejemplo,left_only,right_onlyyboth, como tenemos en el siguiente resultado.Aquí, “ambos” significa que si la clave de combinación de la observación (fila) se encuentra en ambos conjuntos de datos,
left_onlymuestra que la clave de combinación de la observación se encuentra solo en el conjunto de datos izquierdo, mientras queright_onlyindica que la combinación de la observación la clave se encuentra solo en el conjunto de datos derecho.PRODUCCIÓN:
sections points _merge 0 A 19 both 1 B 23 both 2 C 20 both 3 D 15 left_only 4 E 31 left_only 5 F 24 right_only 6 G 30 right_only -
Realice la combinación izquierda.
lef_anti_join = outer_join[(outer_join._merge == "left_only")].drop("_merge", axis=1) print(lef_anti_join)Primero, usamos
outer_join[(outer_join._merge=='left_only')]para recuperar todas las filas que tienen un valorleft_onlyen la columna_merge, luego lo encadenamos con el método.drop(), que elimina la columna_mergedel marco de datos de salida.PRODUCCIÓN:
sections points 3 D 15 4 E 31Ahora vea, obtenemos columnas del marco de datos izquierdo (
df1), excluyendo la intersección. -
Vea el código fuente completo para realizar el anti-join izquierdo en Pandas.
import pandas as pd # first DataFrame df1 = pd.DataFrame( {"sections": ["A", "B", "C", "D", "E"], "points": [19, 23, 20, 15, 31]} ) print("First DataFrame:") print(df1) # second DataFrame df2 = pd.DataFrame( {"sections": ["A", "B", "C", "F", "G"], "points": [19, 23, 20, 24, 30]} ) print("\n\nSecond DataFrame:") print(df2) # outer join outer_join = df1.merge(df2, how="outer", indicator=True) # left anti join lef_anti_join = outer_join[(outer_join._merge == "left_only")].drop("_merge", axis=1) print("\n\nLeft Anti-join:") print(lef_anti_join)PRODUCCIÓN:
First DataFrame: sections points 0 A 19 1 B 23 2 C 20 3 D 15 4 E 31 Second DataFrame: sections points 0 A 19 1 B 23 2 C 20 3 F 24 4 G 30 Left Anti-join: sections points 3 D 15 4 E 31
Realice el Anti-Join Correcto en Pandas
Hemos aprendido paso a paso cómo realizar la combinación izquierda en Pandas. La combinación correcta también se puede hacer de manera similar, pero aquí seleccionaremos aquellas filas con un valor right_only en la columna _merge.
Código de ejemplo:
import pandas as pd
# first DataFrame
df1 = pd.DataFrame(
{"sections": ["A", "B", "C", "D", "E"], "points": [19, 23, 20, 15, 31]}
)
print("First DataFrame:")
print(df1)
# second DataFrame
df2 = pd.DataFrame(
{"sections": ["A", "B", "C", "F", "G"], "points": [19, 23, 20, 24, 30]}
)
print("\n\nSecond DataFrame:")
print(df2)
# outer join
outer_join = df1.merge(df2, how="outer", indicator=True)
# right anti join
right_anti_join = outer_join[(outer_join._merge == "right_only")].drop("_merge", axis=1)
print("\n\nRight Anti-join:")
print(right_anti_join)
Producción :
First DataFrame:
sections points
0 A 19
1 B 23
2 C 20
3 D 15
4 E 31
Second DataFrame:
sections points
0 A 19
1 B 23
2 C 20
3 F 24
4 G 30
Right Anti-join:
sections points
5 F 24
6 G 30
Esta vez, obtenemos columnas del marco de datos derecho (df2), excluyendo la intersección.
