SciPy scipy.stats.multivariate_normal
L’objet Python Scipy scipy.stats.multivariate_normal est utilisé pour analyser la distribution normale multivariée et calculer différents paramètres liés à la distribution à l’aide des différentes méthodes disponibles.
Syntaxe pour générer la fonction de densité de probabilité à l’aide de l’objet scipy.stats.multivariate_normal
scipy.stats.multivariate_normal.pdf(x, mean=None, cov=1, allow_singular=False)
Paramètres:
x |
Valeurs dont pdf est à déterminer. La deuxième dimension de cette variable représente les composants de l’ensemble de données. |
mean |
Élément de type tableau qui représente la moyenne de la distribution. Chaque valeur du tableau représente la valeur de chaque composant du jeu de données. La valeur par défaut est 0. |
cov |
Matrice de covariance des données. La valeur par défaut est 1. |
allow_singular |
S’il est défini sur True, le singulier cov peut être autorisé. La valeur par défaut est False |
Retourner:
Une structure de type tableau qui contient la valeur de probabilité pour chaque élément de x.
Exemple : Générer une fonction de densité de probabilité à l’aide de la méthode scipy.stats.multivariate_normal.pdf
import numpy as np
from scipy.stats import multivariate_normal
mean = np.array([0.4, 0.8])
cov = np.array([[0.1, 0.3], [0.3, 1.0]])
x = np.random.uniform(size=(5, 2))
y = multivariate_normal.pdf(x, mean=mean, cov=cov)
print("Tha data and corresponding pdfs are:")
print("Data-------PDF value")
for i in range(len(x)):
print(x[i], end=" ")
print("------->", end=" ")
print(y[i], end="\n")
Production :
Tha data and corresponding pdfs are:
Data-------PDF value
[0.60156002 0.53917659] -------> 0.030687330659191728
[0.60307471 0.25205368] -------> 0.0016016741361277501
[0.27254519 0.06817383] -------> 0.7968146411119688
[0.33630808 0.21039553] -------> 0.7048988855032084
[0.0009666 0.52414497] -------> 0.010307396714783708
Dans l’exemple ci-dessus, x représente le tableau de valeurs dont pdf est à trouver. Les lignes représentent chaque valeur de x dont le pdf est à trouver, et les colonnes représentent le nombre de composantes utilisées pour représenter chaque valeur.
Ici, chaque valeur de x est constituée de deux composantes, et donc c’est un vecteur de longueur 2. La moyenne sera un vecteur de longueur égale au nombre de composantes. De même, si d est le nombre de composants dans le jeu de données, cov sera une matrice carrée symétrique de taille d*d.
La méthode scipy.stats.multivariate_normal.pdf prend l’entrée x, moyenne et la matrice de covariance cov et génère un vecteur d’une longueur égale au nombre de lignes dans x où chaque valeur dans la sortie le vecteur représente la valeur pdf pour chaque ligne dans x.
Exemple : Tirer des échantillons aléatoires d’une distribution normale multivariée à l’aide de la méthode scipy.stats.multivariate_normal.rvs
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import multivariate_normal
mean = np.array([0.4, 0.8])
cov = np.array([[0.1, 0.3], [0.3, 1.0]])
x = multivariate_normal.rvs(mean, cov, 100)
plt.scatter(x[:, 0], x[:, 1])
plt.show()
Production :
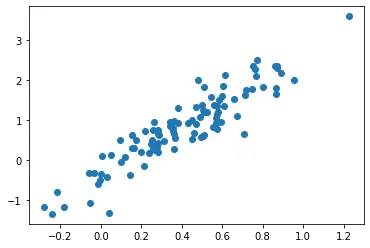
Le graphique ci-dessus représente le nuage de points de 20 échantillons aléatoires tirés au hasard d’une distribution normale multivariée à deux caractéristiques. La distribution a une valeur mean de [0.4,0.8] où 0.4 représente la valeur moyenne de la première caractéristique et 0.8 la moyenne de la deuxième caractéristique. Enfin, nous dessinons le diagramme de dispersion des échantillons aléatoires avec la première caractéristique le long de l’axe des X et la deuxième caractéristique le long de l’axe des Y.
D’après le graphique, il est clair que la plupart des points d’échantillonnage sont centrés autour de [0.4,0.8], représentant la moyenne de la distribution multivariée.
Exemple : obtenir une fonction de distribution cumulative à l’aide de la méthode scipy.stats.multivariate_normal.cdf
Fonction de distribution cumulative (CDF) est l’intégrale de pdf. CDF nous montre que toute valeur tirée de la population aura une valeur de probabilité inférieure ou égale à une certaine valeur. Nous pouvons calculer cdf des points de distribution multivariée en utilisant la méthode scipy.stats.multivariate_normal.cdf.
import numpy as np
from scipy.stats import multivariate_normal
mean = np.array([0.4, 0.8])
cov = np.array([[0.1, 0.3], [0.3, 1.0]])
x = np.random.uniform(size=(5, 2))
y = multivariate_normal.cdf(x, mean=mean, cov=cov)
print("Tha data and corresponding cdfs are:")
print("Data-------CDF value")
for i in range(len(x)):
print(x[i], end=" ")
print("------->", end=" ")
print(y[i], end="\n")
Production :
Tha data and corresponding cdfs are:
Data-------CDF value
[0.89027577 0.06036432] -------> 0.22976054289355996
[0.78164237 0.09611703] -------> 0.24075282906929418
[0.53051197 0.63041372] -------> 0.4309184323329717
[0.15571201 0.97173575] -------> 0.21985053519541042
[0.72988545 0.22477096] -------> 0.28256819625802715
Dans l’exemple ci-dessus, x représente le tableau de points où se trouve cdf. Les lignes représentent chaque valeur de x à laquelle cdf doit être trouvée, et les colonnes représentent le nombre de composants utilisés pour représenter chaque valeur.
Ici, chaque valeur de x est constituée de deux composantes, et donc c’est un vecteur de longueur 2. La moyenne sera un vecteur de longueur égale au nombre de composantes. De même, si d est le nombre de composants dans le jeu de données, cov sera une matrice carrée symétrique de taille d*d.
La méthode scipy.stats.multivariate_normal.cdf prend l’entrée x, mean et la matrice de covariance cov et génère un vecteur d’une longueur égale au nombre de lignes dans x où chaque valeur dans la sortie le vecteur représente la valeur cdf pour chaque ligne dans x.

Suraj Joshi is a backend software engineer at Matrice.ai.
LinkedIn