Verwenden Sie Multiprocessing auf einem Pandas DataFrame
- Einführung in Multiprocessing
- Bedeutung der Verwendung von Multiprocessing
- Verwenden Sie Multiprocessing auf einem Pandas DataFrame

Dieses Tutorial stellt Multiprocessing in Python vor und informiert anhand von Codebeispielen und grafischen Darstellungen darüber. Es hebt auch die Bedeutung von Multiprocessing hervor und zeigt, wie man das multiprocessing-Modul mit einem Pandas-Datenrahmen verwendet.
Einführung in Multiprocessing
Multiprocessing bedeutet, dass das System mehrere Prozessoren gleichzeitig unterstützen kann. Beim Multiprocessing werden Anwendungen in kleinere Routinen aufgeteilt, die unabhängig oder weniger unabhängig laufen können.
Das Betriebssystem weist diese Threads verschiedenen Prozessoren zu, wodurch die Leistung des Systems verbessert wird. Wie? Lassen Sie es uns mit dem folgenden einfachen Programm verstehen.
Beispielcode:
import time
start = time.perf_counter()
def print_something():
print("Sleeping for 1 second.")
time.sleep(1)
print("Done with sleeping.")
print_something()
finish = time.perf_counter()
print(f"Completed in {round(finish-start,2)} second(s)")
AUSGANG:
Sleeping for 1 second.
Done with sleeping.
Completed in 1.01 second(s)
Die obige Ausgabe klingt richtig, weil wir im Code Fence zuerst das Modul time importiert haben, mit dem wir messen werden, wie lange es dauert, bis das Skript ausgeführt wird. Um das zu messen, haben wir die start- und End-Zeit mit start = time.perf_counter() und finish = time.perf_counter() berechnet.
Wir haben auch eine Funktion namens print_something(), die etwas druckt, für eine Sekunde schläft und eine weitere Anweisung druckt. Wir rufen diese Funktion auf und geben schließlich die letzte Anweisung aus, die zeigt, dass wir das Skript abgeschlossen haben.
Wenn wir jetzt print_something() zweimal ausführen, dauert es fast zwei Sekunden. Sie können dies unten überprüfen.
Beispielcode:
import time
start = time.perf_counter()
def print_something():
print("Sleeping for 1 second.")
time.sleep(1)
print("Done with sleeping.")
print_something()
print_something()
finish = time.perf_counter()
print(f"Completed in {round(finish-start,2)} second(s)")
AUSGANG:
Sleeping for 1 second.
Done with sleeping.
Sleeping for 1 second.
Done with sleeping.
Completed in 2.02 second(s)
Jetzt schläft das Programm zweimal für eine Sekunde, sodass es fast zwei Sekunden dauert, um das Skript zu beenden.
Wir können also sehen, dass jedes Mal, wenn wir diese print_something()-Funktion ausführen, das Skript um etwa eine Sekunde verlängert wird. Unser Skript wartet nur eine Sekunde lang und wartet dann auf die nächste Funktion und wartet eine weitere Sekunde.
Dann sind wir an diesem Punkt fertig und unser Skript ist beendet. Wir können es anhand der folgenden grafischen Darstellung verstehen.
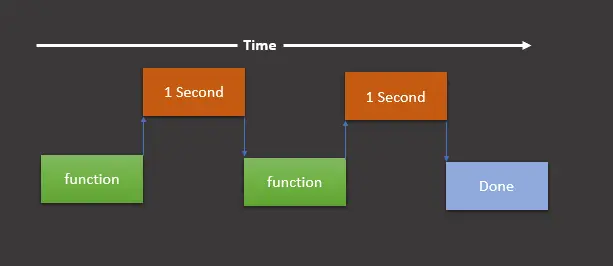
Diese grafische Darstellung zeigt, dass wir eine Funktion ausführen (in unserem Fall print_something()), eine Sekunde warten, die Funktion erneut ausführen, dann eine weitere Sekunde warten, und sobald dies erledigt ist, wird der endgültige print gedruckt Erklärung, die zeigt, dass wir fertig sind.
Wie in der obigen grafischen Darstellung dargestellt, wird die Ausführung des Skripts in dieser Reihenfolge als synchron ausgeführt bezeichnet.
Wenn wir nun eine Aufgabe haben, die nicht synchron ausgeführt werden muss, können wir das multiprocessing-Modul verwenden, um diese Aufgaben auf die anderen CPUs aufzuteilen und sie gleichzeitig auszuführen.
Denken Sie daran, dass multithreading nicht dasselbe ist wie multiprocessing. Sie können den Unterschied hier finden.
Die grafische Darstellung sieht wie folgt aus, wenn wir das Modul multiprocessing verwenden sollen.
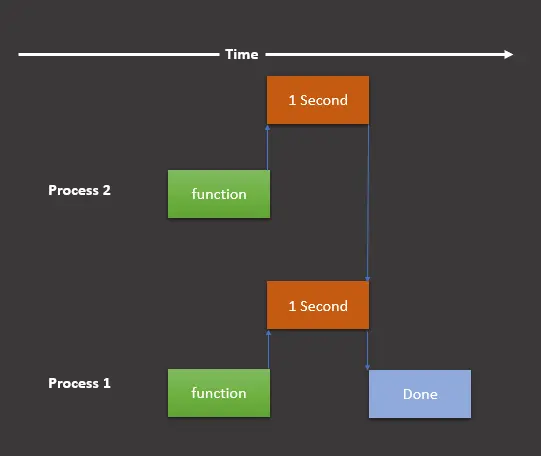
Hier haben wir immer noch zwei Tasks, aber teilen diese in zwei Prozesse auf, die gleichzeitig auf verschiedenen Prozessen laufen. Lassen Sie uns nun diese grafische Darstellung in unserem Programm wie folgt implementieren:
import multiprocessing
import time
start = time.perf_counter()
def print_something():
print("Sleeping for 1 second.")
time.sleep(1)
print("Done with sleeping.")
process1 = multiprocessing.Process(target=print_something)
process2 = multiprocessing.Process(target=print_something)
process1.start()
process2.start()
process1.join()
process2.join()
finish = time.perf_counter()
print(f"Completed in {round(finish-start,2)} second(s)")
AUSGANG:
Sleeping for 1 second.
Done with sleeping.
Sleeping for 1 second.
Done with sleeping.
Completed in 1.02 second(s)
Wie wir jetzt sehen können, dauert das Skript eine Sekunde statt zwei. Das obige Skript ähnelt dem vorherigen, abgesehen von einigen Änderungen.
Wir haben das Modul multiprocessing importiert, mit dem wir Prozesse erstellen werden. Dann erstellen wir zwei Prozesse mit multiprocessing.Process(target=print_something) und speichern sie in process1 und process2.
Danach starten wir diese beiden Prozesse mit process1.start() und process2.start(). Wir haben die Methode .join() verwendet, um zu vermeiden, dass der Rest unseres Skripts ausgeführt wird, bevor die Prozesse abgeschlossen sind.
Das heißt, wenn wir die Methode .join() weglassen, werden die folgenden zwei Anweisungen ausgeführt, bevor die Prozesse beendet werden:
finish = time.perf_counter()
print(f"Completed in {round(finish-start,2)} second(s)")
Wir können es lernen, indem wir den folgenden Beispielcode verwenden:
import multiprocessing
import time
start = time.perf_counter()
def print_something():
print("Sleeping for 1 second.")
time.sleep(1)
print("Done with sleeping.")
process1 = multiprocessing.Process(target=print_something)
process2 = multiprocessing.Process(target=print_something)
process1.start()
process2.start()
# process1.join()
# process2.join()
finish = time.perf_counter()
print(f"Completed in {round(finish-start,2)} second(s)")
AUSGANG:
Completed in 0.01 second(s)
Sleeping for 1 second.
Done with sleeping.
Sleeping for 1 second.
Done with sleeping.
Wie wir sehen können, druckt es die Completed-Anweisung vor den Sleeping- und Done-Anweisungen. Um das zu vermeiden, können wir die Methode .join() verwenden.
Bedeutung der Verwendung von Multiprocessing
Angenommen, wir haben eine Maschine (PC/Laptop) mit einem Prozessor. Wenn wir ihm mehrere Prozesse gleichzeitig zuweisen, muss er jede Aufgabe stören oder unterbrechen und von einer zur anderen wechseln, um alle Prozesse weiterlaufen zu lassen.
Hier kommt das Konzept des Multiprocessing ins Spiel. Ein Multiprozessor-Computer kann mehrere zentrale Prozessoren (Multiprozessor) oder eine Rechenkomponente mit zwei oder mehr unabhängigen eigentlichen Verarbeitungseinheiten haben, die als Kerne bekannt sind (Multi-Core-Prozessoren).
Hier führt die CPU problemlos mehrere Aufgaben gleichzeitig aus, wobei jede Aufgabe ihren eigenen Prozess verwendet. Auf diese Weise beschleunigen wir unser Programm und sparen viel Zeit und Kosten.
Verwenden Sie Multiprocessing auf einem Pandas DataFrame
Wir haben genügend Wissen über das Modul multiprocessing, seine grundlegende Verwendung und seine Bedeutung. Lassen Sie uns lernen, wie wir dieses Modul mit Datenrahmen verwenden können.
-
Importieren Sie die Bibliotheken und Module.
Importieren Sie zunächst alle erforderlichen Module und Bibliotheken.
import pandas as pd from geopy.distance import geodesic from itertools import combinations import multiprocessing as mp -
Erstellen Sie einen Datenrahmen.
Wir erstellen einen Datenrahmen, der die Spalten
serial_number,column_name,latundlonund ihre Werte enthält.df = pd.DataFrame( { "serial_number": [1, 2, 3, 4, 5, 6, 7, 8, 9, 0], "column_name": ["aa", "aa", "aa", "bb", "bb", "bb", "bb", "cc", "cc", "cc"], "lat": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10], "lon": [21, 22, 23, 24, 25, 26, 27, 28, 29, 30], } ) -
Teilen Sie die Aufgaben auf.
Wir teilen die Aufgabe zwischen Prozessen auf und senden wahrscheinlich jedes Tupel
(grp, lst)an einen separaten Prozess. Die folgenden Codezeilen tun dasselbe:grp_lst_args = list(df.groupby("column_name").groups.items()) print(grp_lst_args) # [('aa', [0, 1, 2]), ('cc', [7, 8, 9]), ('bb', [3, 4, 5, 6])]Danach senden wir jedes Tupel in einem separaten Prozess als Argument an eine Funktion (in diesem Fall
calc_dist()). Schauen wir uns das unten an. -
Senden Sie die Liste der Tupel an eine Funktion.
calc_dist()nimmt einen Parameter vom TypListe, um die Entfernung zu berechnen, und gibt ihn als Datenrahmen zurück. Beachten Sie, dasspd.DataFrame()verwendet wird, um in einen Datenrahmen zu konvertieren.Hier enthält die Liste drei Tupel
[('aa', [0, 1, 2]), ('cc', [7, 8, 9]), ('bb', [3, 4, 5, 6])], die wir im vorherigen erstellt haben.def calc_dist(arg): grp, lst = arg return pd.DataFrame( [ [ grp, df.loc[c[0]].serial_number, df.loc[c[1]].serial_number, geodesic(df.loc[c[0], ["lat", "lon"]], df.loc[c[1], ["lat", "lon"]]), ] for c in combinations(lst, 2) ], columns=["column_name", "machine_A", "machine_B", "Distance"], ) -
Multiprocessing implementieren.
An dieser Stelle verwenden wir Multiprocessing, um gleichzeitig die Funktion
calc_dist()für jedes Tupel aufzurufen. Im folgenden Code verwenden wirPool()für die parallele Ausführung der Funktioncalc_dist()für jedes Tupel.pool = mp.Pool(processes=(mp.cpu_count() - 1)) results = pool.map(calc_dist, grp_lst_args) pool.close() pool.join() results_df = pd.concat(results)
Der vollständige Quellcode ist unten angegeben:
import pandas as pd
from geopy.distance import geodesic
from itertools import combinations
import multiprocessing as mp
df = pd.DataFrame(
{
"serial_number": [1, 2, 3, 4, 5, 6, 7, 8, 9, 0],
"column_name": ["aa", "aa", "aa", "bb", "bb", "bb", "bb", "cc", "cc", "cc"],
"lat": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
"lon": [21, 22, 23, 24, 25, 26, 27, 28, 29, 30],
}
)
grp_lst_args = list(df.groupby("column_name").groups.items())
print(grp_lst_args)
# [('aa', [0, 1, 2]), ('cc', [7, 8, 9]), ('bb', [3, 4, 5, 6])]
def calc_dist(arg):
grp, lst = arg
return pd.DataFrame(
[
[
grp,
df.loc[c[0]].serial_number,
df.loc[c[1]].serial_number,
geodesic(df.loc[c[0], ["lat", "lon"]], df.loc[c[1], ["lat", "lon"]]),
]
for c in combinations(lst, 2)
],
columns=["column_name", "machine_A", "machine_B", "Distance"],
)
pool = mp.Pool(processes=(mp.cpu_count() - 1))
results = pool.map(calc_dist, grp_lst_args)
pool.close()
pool.join()
results_df = pd.concat(results)
results_df
AUSGANG:
| | column_name | machine_A | machine_B | Distance |
| ---- | ----------- | --------- | --------- | --------------------- |
| 0 | aa | 1 | 2 | 156.87614940188664 km |
| 1 | aa | 1 | 3 | 313.70544546930296 km |
| 2 | aa | 2 | 3 | 156.82932911607335 km |
| 0 | bb | 4 | 5 | 156.66564184752647 km |
| 1 | bb | 4 | 6 | 313.21433304645853 km |
| 2 | bb | 4 | 7 | 469.6225353706956 km |
| 3 | bb | 5 | 6 | 156.54889742502786 km |
| 4 | bb | 5 | 7 | 312.95759748703733 km |
| 5 | bb | 6 | 7 | 156.40899678081678 km |
| 0 | cc | 8 | 9 | 156.0601654009819 km |
| 1 | cc | 8 | 0 | 311.91099818906036 km |
| 2 | cc | 9 | 0 | 155.85149814424545 km |

Verwandter Artikel - Pandas DataFrame
- Wie man Pandas DataFrame-Spaltenüberschriften als Liste erhält
- Pandas DataFrame-Spalte löschen
- Wie man DataFrame-Spalte in Datetime in Pandas konvertiert
- Wie konvertiert man eine Fließkommazahl in eine Ganzzahl in Pandas DataFrame
- Wie man Pandas-DataFrame nach den Werten einer Spalte sortiert
- Wie erhält man das Aggregat der Pandas gruppenweise und sum