Pandas value_counts Prozentsatz
-
Verwenden Sie die Funktion
value_counts()von Panda, um Werte aus dem Datenrahmen in Python zu zählen -
Wenden Sie die Funktion
value_counts()auf die Spaltenliste an - Konvertieren Sie die Häufigkeit in Prozent in Python

Wir werden lernen, wie man die Funktion value_counts() verwendet, um Werte zu zählen, und sehen, wie man diese Funktion auf eine Liste von Datenrahmenspalten anwendet. Wir werden auch lernen, wie man Häufigkeiten in Prozent in Python umwandelt.
Verwenden Sie die Funktion value_counts() von Panda, um Werte aus dem Datenrahmen in Python zu zählen
Die Funktion value_counts() funktioniert ein wenig ähnlich wie die Funktion groupby(), aber es gibt auch Vorteile bei der Verwendung der Funktion value_counts().
Um diese Pandas-Funktion zu untersuchen, verwenden wir einen Mitarbeiterdatensatz für unsere Analyse und ermitteln den Prozentsatz der Mitarbeiter in jeder Abteilung.
Das Ziel ist es, einen einfachen Gehaltsdatenrahmen zu erstellen und das oberste Segment der Mitarbeiter nach Gehalt in der Abteilung zu finden und welche Abteilungen von Mitarbeitern verlassen werden. Und wir werden die Häufigkeit in einen Prozentsatz umwandeln; All dies kann mit der Funktion value_counts() erledigt werden.
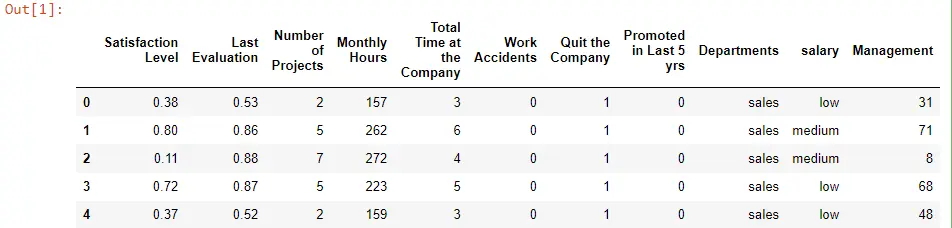
Beginnen wir damit, Pandas zu importieren und als pd zu speichern, was unsere Variable ist, und dann verwenden wir die pd-Variable, um die read_csv()-Funktion aufzurufen und unsere Datendatei mit dem Namen HR_file.csv zu übergeben.
Wir haben Zugriff auf die Funktion head(), die uns die ersten fünf Zeilen und einige Spalten liefert.
import pandas as pd
Employee_Data = pd.read_csv("HR_file.csv")
Employee_Data.head()
Wir können eine Spalte, an der wir interessiert sind, immer mit einer eckigen Klammer isolieren, und innerhalb der Klammern nennen wir die Spalte Gehalt. Jetzt verwenden wir die Funktion value_counts().
Employee_Data["salary"].value_counts()
Wir können die niedrige, mittlere und hohe Gehaltsverteilung erkennen.
low 7316
medium 6446
high 1237
Name: salary, dtype: int64
den normalisieren-Parameter
Wir können immer sehen, was diese Funktion benötigt, indem wir Shift+Tab drücken, und wir können sehen, dass es einige verschiedene Parameter gibt, die wir verwenden können, zum Beispiel normalisieren.
Wir können sehen, dass die überwiegende Mehrheit unserer Gehälter in der Kategorie niedrig liegt, aber wenn wir einen Prozentsatz erhalten wollten, würden wir normalisieren gleich true verwenden.
Employee_Data["salary"].value_counts(normalize=True)
Ausgang:
low 0.487766
medium 0.429762
high 0.082472
Name: salary, dtype: float64
Wir können die Spalte Gehalt einfach mit der Spalte Abteilungen ändern.
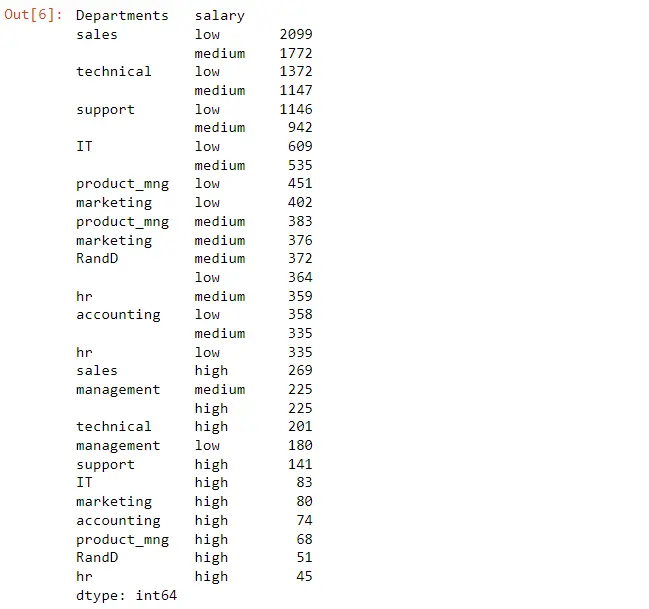
Employee_Data["Departments "].value_counts(normalize=True)
Wir können die Aufschlüsselung der Abteilungen sehen, und wir haben das immer noch normalisiert.
sales 0.276018
technical 0.181345
support 0.148610
IT 0.081805
product_mng 0.060137
marketing 0.057204
RandD 0.052470
accounting 0.051137
hr 0.049270
management 0.042003
Name: Departments , dtype: float64
Wenn wir das nicht normalisieren wollten, würden wir es entfernen, was in absteigender Reihenfolge angezeigt wird.
Employee_Data["Departments "].value_counts()
Ausgang:
sales 4140
technical 2720
support 2229
IT 1227
product_mng 902
marketing 858
RandD 787
accounting 767
hr 739
management 630
Name: Departments , dtype: int64
Wenden Sie die Funktion value_counts() auf die Spaltenliste an
Das nächste, was wir tun können, ist, was die Schnittmenge zwischen Mitarbeitern nach Gehalt und Abteilungen ist. Wir werden mehr als eine Spalte verwenden, indem wir eine Liste verwenden, und innerhalb der Liste werden wir Gehalt und Abteilungen übergeben und dann die Funktion value_counts() darauf anwenden.
Wenn Sie ein kleines Leerzeichen vor Abteilungen sehen, dann fügt die Abteilung aus irgendeinem Grund ein Leerzeichen danach hinzu, also fügen wir ein Leerzeichen mit dieser Spalte hinzu.
Employee_Data[["Departments ", "salary"]].value_counts()
Wir können die meisten Verkäufe unserer Mitarbeiter sehen, und die meisten davon sind im niedrigen Bereich, und wenn wir dann hierher kommen, können wir sehen, dass es im Verkauf ein hohes Gehalt gibt, aber nur 269 Leute. Und 2099 liegt in einem niedrigen Gehaltsbereich.
Konvertieren Sie die Häufigkeit in Prozent in Python
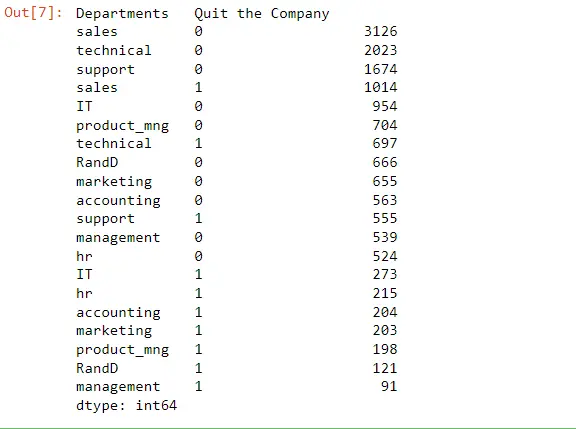
Nun wollen wir wissen, welche Abteilungen von Mitarbeitern verlassen werden. Dazu verwenden wir die Spalte Unternehmen verlassen.
Employee_Data[["Departments ", "Quit the Company"]].value_counts()
Wie wir sehen, ist 1 die Stelle in Bezug darauf, wer das Unternehmen verlassen hat, also würden wir uns nur die ansehen. Die Mehrheit der Personen verließ die Abteilung Verkauf.
Jetzt müssen wir nur noch Verkäufe auswerten; Wir könnten unsere Spalte Abteilungen leicht isolieren, indem wir eine Bedingung erstellen und eine Maske erhalten.
Employee_Data["Departments "] == "sales"
Jetzt kapseln wir diese Bedingung in Klammern und speichern sie in einer Variablen namens sales. Mit Umsatz betrachten wir die Wertzahlen derjenigen, die das Unternehmen verlassen haben.
sales = Employee_Data[Employee_Data["Departments "] == "sales"]
sales["Quit the Company"].value_counts()
Jetzt können wir die Zahl sehen, die das Unternehmen verlassen hat.
0 3126
1 1014
Name: Quit the Company, dtype: int64
Es kann gut sein, dies in Prozent zu sehen.
sales = Employee_Data[Employee_Data["Departments "] == "sales"]
sales["Quit the Company"].value_counts(normalize=True)
Ausgang:
0 0.755072
1 0.244928
Name: Quit the Company, dtype: float64

Hello! I am Salman Bin Mehmood(Baum), a software developer and I help organizations, address complex problems. My expertise lies within back-end, data science and machine learning. I am a lifelong learner, currently working on metaverse, and enrolled in a course building an AI application with python. I love solving problems and developing bug-free software for people. I write content related to python and hot Technologies.
LinkedIn