Pandas Anti-Beitritt
- Pandas Anti-Join und seine Typen
- Führen Sie den linken Anti-Join in Pandas durch
- Führen Sie den richtigen Anti-Join in Pandas durch

Dieses Tutorial beschreibt die Anti-Joins von Pandas, beschreibt kurz ihre Typen und demonstriert jeden anhand von Beispielcodes.
Pandas Anti-Join und seine Typen
Durch die Verwendung von Anti-Join können wir alle Zeilen (auch bekannt als Datensätze und Dokumente) in einem Datensatz zurückgeben, die im anderen Datensatz keinen übereinstimmenden Wert finden. Diese werden verwendet, um Datensätze gemäß den Projektanforderungen zu manipulieren.
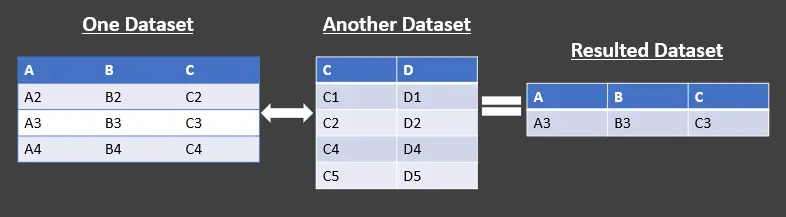
Es gibt zwei Arten von Anti-Joins in Pandas, die unten aufgeführt sind:
- Linker Anti-Join - Gibt die Datensätze im linken Datensatz zurück, die keine übereinstimmenden Datensätze im rechten Datensatz haben.
- Right Anti-Join - Gibt die Datensätze im rechten Datensatz zurück, die nicht mit denen im linken Datensatz übereinstimmen.
Siehe obige tabellarische Darstellung. Wir verwenden den linken Anti-Join, der den linken Datensatz ohne die Schnittmenge zurückgibt.
Beachten Sie, dass nur Spalten aus dem linken Dataset und nicht aus dem rechten zurückgegeben werden.
In ähnlicher Weise wird bei Verwendung des richtigen Anti-Joins der richtige Datensatz zurückgegeben, ohne die Schnittmenge. Wie Left Anti-Join gibt es auch nur Spalten aus dem rechten Dataset und nicht aus dem linken zurück.
Lassen Sie uns lernen, wie wir diese beiden Anti-Joins in Pandas verwenden können. Beachten Sie, dass Sie über ausreichende Kenntnisse von SQL-Joins verfügen müssen, um die Anti-Joins sicher zu erfassen.
Führen Sie den linken Anti-Join in Pandas durch
-
Importieren Sie die Bibliothek.
import pandas as pdZuerst importieren wir die
pandas-Bibliothek, um mit Datenrahmen zu spielen. -
Erstellen Sie zwei Datenrahmen.
# first DataFrame df1 = pd.DataFrame( {"sections": ["A", "B", "C", "D", "E"], "points": [19, 23, 20, 15, 31]} ) print("First DataFrame:") print(df1) # second DataFrame df2 = pd.DataFrame( {"sections": ["A", "B", "C", "F", "G"], "points": [19, 23, 20, 24, 30]} ) print("\n\nSecond DataFrame:") print(df2)Wir erstellen zwei Datenrahmen mit Muster-
Punktenfür verschiedeneAbschnitte, die Sie unten sehen können.AUSGANG:
First DataFrame: sections points 0 A 19 1 B 23 2 C 20 3 D 15 4 E 31 Second DataFrame: sections points 0 A 19 1 B 23 2 C 20 3 F 24 4 G 30 -
Führen Sie den äußeren Join aus.
outer_join = df1.merge(df2, how="outer", indicator=True) print(outer_join)Um einen Anti-Join durchzuführen, müssen wir den Outer Join durchlaufen, der die übereinstimmenden und nicht übereinstimmenden Werte aus einem oder beiden Datensätzen zurückgibt. Wir erhalten übereinstimmende und nicht übereinstimmende Werte aus beiden Datensätzen (Sie können dies in der folgenden Ausgabe sehen).
Hier wird die Methode
merge()verwendet, um die Daten zweier Datenrahmen zu aktualisieren, indem sie mit einer bestimmten Methode(n) zusammengeführt werden. Wir verwenden einige Parameter, um zu steuern, welche Werte ersetzt und welche beibehalten werden sollen.df2- Dies ist ein weiterer Datenrahmen, mit dem zusammengeführt werden kann.wie- Gibt an, wie zusammengeführt wird. Es ist ein optionaler Parameter, dessen Wertelinks,rechts,außen,innenoderquersein können; standardmäßig ist esinner.indicator– Kann aufTrue,Falseoder einen Wert vom Typ String gesetzt werden. Wenn wir es aufTruesetzen, fügt es dem Ausgabedatenrahmen die Spalte_mergehinzu, die die Informationen über eine Quelle jeder Zeile enthält.
Wir können der Spalte
_mergeauch einen anderen Namen geben, indem wir ein String-Argument angeben. Diese Spalte enthält die kategorialen Typwerte, z. B.left_only,right_onlyundboth, wie in der folgenden Ausgabe.Dabei bedeutet
both, dass der Zusammenführungsschlüssel der Beobachtung (Zeile) in beiden Datensätzen gefunden wird,left_onlyzeigt an, dass der Zusammenführungsschlüssel der Beobachtung nur im linken Datensatz gefunden wird, währendright_onlyanzeigt, dass die Beobachtung zusammengeführt wird Der Schlüssel wird nur im rechten Datensatz gefunden.AUSGANG:
sections points _merge 0 A 19 both 1 B 23 both 2 C 20 both 3 D 15 left_only 4 E 31 left_only 5 F 24 right_only 6 G 30 right_only -
Führen Sie den linken Anti-Join aus.
lef_anti_join = outer_join[(outer_join._merge == "left_only")].drop("_merge", axis=1) print(lef_anti_join)Zuerst verwenden wir
outer_join[(outer_join._merge=='left_only')], um alle Zeilen abzurufen, die einenleft_only-Wert in der_merge-Spalte haben, und verketten ihn dann mit der.drop()-Methode, die löscht die Spalte_mergeaus dem Ausgangsdatenrahmen.AUSGANG:
sections points 3 D 15 4 E 31Sehen Sie, wir erhalten Spalten aus dem linken Datenrahmen (
df1), ohne den Schnittpunkt. -
Sehen Sie sich den vollständigen Quellcode an, um den linken Anti-Join in Pandas durchzuführen.
import pandas as pd # first DataFrame df1 = pd.DataFrame( {"sections": ["A", "B", "C", "D", "E"], "points": [19, 23, 20, 15, 31]} ) print("First DataFrame:") print(df1) # second DataFrame df2 = pd.DataFrame( {"sections": ["A", "B", "C", "F", "G"], "points": [19, 23, 20, 24, 30]} ) print("\n\nSecond DataFrame:") print(df2) # outer join outer_join = df1.merge(df2, how="outer", indicator=True) # left anti join lef_anti_join = outer_join[(outer_join._merge == "left_only")].drop("_merge", axis=1) print("\n\nLeft Anti-join:") print(lef_anti_join)AUSGANG:
First DataFrame: sections points 0 A 19 1 B 23 2 C 20 3 D 15 4 E 31 Second DataFrame: sections points 0 A 19 1 B 23 2 C 20 3 F 24 4 G 30 Left Anti-join: sections points 3 D 15 4 E 31
Führen Sie den richtigen Anti-Join in Pandas durch
Wir haben Schritt für Schritt gelernt, wie man in Pandas einen linken Anti-Join durchführt. Der rechte Anti-Join kann auch auf ähnliche Weise erfolgen, aber hier wählen wir die Zeilen mit einem right_only-Wert in der _merge-Spalte aus.
Beispielcode:
import pandas as pd
# first DataFrame
df1 = pd.DataFrame(
{"sections": ["A", "B", "C", "D", "E"], "points": [19, 23, 20, 15, 31]}
)
print("First DataFrame:")
print(df1)
# second DataFrame
df2 = pd.DataFrame(
{"sections": ["A", "B", "C", "F", "G"], "points": [19, 23, 20, 24, 30]}
)
print("\n\nSecond DataFrame:")
print(df2)
# outer join
outer_join = df1.merge(df2, how="outer", indicator=True)
# right anti join
right_anti_join = outer_join[(outer_join._merge == "right_only")].drop("_merge", axis=1)
print("\n\nRight Anti-join:")
print(right_anti_join)
AUSGANG:
First DataFrame:
sections points
0 A 19
1 B 23
2 C 20
3 D 15
4 E 31
Second DataFrame:
sections points
0 A 19
1 B 23
2 C 20
3 F 24
4 G 30
Right Anti-join:
sections points
5 F 24
6 G 30
Diesmal erhalten wir Spalten aus dem rechten Datenrahmen (df2), ohne die Schnittmenge.
