Abfragen ohne Berücksichtigung der Groß-/Kleinschreibung in MongoDB
- Abfragen ohne Berücksichtigung der Groß-/Kleinschreibung in MongoDB
- Verbessern Sie Regex-Abfragen ohne Berücksichtigung der Groß-/Kleinschreibung
-
Verwenden Sie Regex in der
find()-Methode für die Suche ohne Berücksichtigung der Groß-/Kleinschreibung in MongoDB

In diesem Artikel werden Abfragen, bei denen die Groß-/Kleinschreibung nicht berücksichtigt wird, kurz erläutert. Darüber hinaus werden Suchanfragen ohne Berücksichtigung der Groß- und Kleinschreibung ausführlich erläutert.
Dieser Artikel behandelt die folgenden Themen.
- Anfragen ohne Berücksichtigung der Groß-/Kleinschreibung
- Verbessern Sie Groß- und Kleinschreibung bei Regex-Abfragen
- Verwenden Sie Regex in der
find()-Methode für die Suche ohne Berücksichtigung der Groß-/Kleinschreibung
Abfragen ohne Berücksichtigung der Groß-/Kleinschreibung in MongoDB
Indizes ohne Berücksichtigung der Groß-/Kleinschreibung ermöglichen Suchvorgänge, die Zeichenfolgen ohne Rücksicht auf die Groß-/Kleinschreibung vergleichen.
Mit db.collection.createIndex() können Sie einen Index ohne Berücksichtigung der Groß-/Kleinschreibung erstellen, indem Sie den Parameter collation als optionalen Parameter hinzufügen.
db.collection.createIndex( { "key" : 1 },
{ collation: {
locale : <locale>,
strength : <strength>
}
} )
Schließen Sie Folgendes ein, wenn Sie eine Sortierung für einen Index angeben, bei dem die Groß-/Kleinschreibung beachtet wird.
locale- gibt Sprachregeln an.Stärke- wird verwendet, um Vergleichsregeln festzulegen. Der Wert1oder2zeigt eine Sortierung ohne Berücksichtigung der Groß-/Kleinschreibung an.
Verhalten:
Die Verwendung eines Index ohne Berücksichtigung der Groß-/Kleinschreibung wirkt sich nicht auf die Abfrageergebnisse aus; es kann jedoch die Geschwindigkeit verbessern.
Um einen durch Sortierung angegebenen Index zu verwenden, müssen Abfrage- und Sortiervorgänge dieselbe Sortierung wie der Index verwenden. Wenn eine Sammlung eine Sortierung definiert, erben alle Abfragen und Indizes, die diese Sammlung verwenden, diese, es sei denn, sie geben eine andere Sortierung an.
Erstellen Sie einen Index ohne Berücksichtigung der Groß-/Kleinschreibung
Erstellen Sie einen Index mit einer Sortierung und legen Sie die Option Stärke auf 1 oder 2 fest, um einen Index ohne Berücksichtigung der Groß-/Kleinschreibung für die Sammlung ohne Standardsortierung zu verwenden. Um die Sortierung auf Indexebene zu verwenden, müssen Sie dieselbe Sortierung auf Abfrageebene bereitstellen.
Das folgende Beispiel generiert eine Sammlung ohne Standardsortierung und fügt der Spalte type einen Index mit einer Sortierung hinzu, bei der die Groß-/Kleinschreibung nicht berücksichtigt wird.
db.createCollection("fruit")
db.fruit.createIndex( { type: 1},
{ collation: { locale: `en`, strength: 2 } } )
Abfragen müssen dieselbe Sortierung haben, um den Index verwenden zu können.
db.fruit.insertMany( [
{ type: "bloctak" },
{ type: "Bloctak" },
{ type: "BLOCTAK" }
] )
db.fruit.find( { type: "bloctak" } )
//not use index, finds one result
db.fruit.find( { type: "bloctak" } ).collation( { locale: `en`, strength: 2 } )
// uses index, and will find three results
db.fruit.find( { type: "bloctak" } ).collation( { locale: `en`, strength: 1 } )
//not uses the index, finds three results
Indizes ohne Berücksichtigung der Groß-/Kleinschreibung für Sammlungen mit der Standardsortierung
Wenn Sie eine Sammlung mit einer Standardsortierung einrichten, erben alle zukünftigen Indizes diese Sortierung, es sei denn, Sie geben eine andere Sortierung an. Alle Abfragen, die keine Sortierung angeben, erben die Standardsortierung.
Das folgende Beispiel generiert eine Sammlung names mit einer Standardsortierung und indexiert dann das Feld first_name.
db.createCollection("names", { collation: { locale: `en_US`, strength: 2 } } )
db.names.createIndex( { first_name: 1 } ) // inherits the default collation
Fügen Sie eine kleine Sammlung von Namen ein:
db.names.insertMany( [
{ first_name: "Betsy" },
{ first_name: "BETSY"},
{ first_name: "betsy"}
] )
Abfragen zu dieser Sammlung verwenden standardmäßig die bereitgestellte Sortierung und, falls möglich, den Index.
db.names.find( { first_name: "betsy" } )
// inherits the default collation: { collation: { locale: `en_US`, strength: 2 } }
// finds three results
Das vorstehende Verfahren ermittelt alle drei Dokumente mithilfe der Standardsortierung der Sammlung. Es verwendet einen Index für das Feld first_name, um die Effizienz zu verbessern.
Diese Sammlung kann dennoch Suchvorgänge mit Berücksichtigung der Groß-/Kleinschreibung durchführen, indem eine andere Sortierung in der Abfrage angegeben wird.
db.names.find( { first_name: "betsy" } ).collation( { locale: `en_US` } )
// not use the collection`s default collation, finds one result
Die obige Prozedur gibt nur ein Dokument zurück, da sie eine Sortierung ohne bereitgestellten Stärke-Wert verwendet. Es verwendet weder den Index noch die Standardsortierung der Sammlung.
Verbessern Sie Regex-Abfragen ohne Berücksichtigung der Groß-/Kleinschreibung
Wenn Sie häufig Regex-Abfragen ohne Berücksichtigung der Groß-/Kleinschreibung durchführen (mit der Option I), sollten Sie einen Index ohne Berücksichtigung der Groß-/Kleinschreibung einrichten, um Ihre Suchanfragen zu berücksichtigen.
Eine Sortierung für einen Index kann verwendet werden, um sprachspezifische Zeichenfolgenvergleichsregeln bereitzustellen, z. B. Regeln für Groß- und Kleinschreibung und Akzentzeichen. Ein Index ohne Berücksichtigung der Groß-/Kleinschreibung verbessert die Leistung bei Abfragen ohne Berücksichtigung der Groß-/Kleinschreibung erheblich.
Betrachten Sie die folgenden Dokumente in einer Sammlung Mitarbeiter. Außer dem üblichen _id-Index enthält diese Sammlung keine weiteren Indizes.
db={
"employees": [
{
"_id": 1,
"first_name": "Hannah",
"last_name": "Simmons",
"dept": "Engineering"
},
{
"_id": 2,
"first_name": "Michael",
"last_name": "Hughes",
"dept": "Security"
},
{
"_id": 3,
"first_name": "Wendy",
"last_name": "Crawford",
"dept": "Human Resources"
},
{
"_id": 4,
"first_name": "MICHAEL",
"last_name": "FLORES",
"dept": "Sales"
}
]
}
Wenn Ihre Anwendung häufig die Spalte first_name durchsucht, möchten Sie möglicherweise Regex-Abfragen ohne Berücksichtigung der Groß-/Kleinschreibung verwenden, um übereinstimmende Namen zu finden.
Regex ohne Berücksichtigung der Groß-/Kleinschreibung hilft auch beim Abgleich mit Datenformaten, die sich unterscheiden, wie im obigen Beispiel, wo Sie den Vornamen von Michael und MICHAEL haben.
Wenn ein Benutzer nach michael sucht, kann das Programm die folgende Abfrage ausführen.
db.employees.find({
first_name: {
$regex: "michael",
$options: "i"
}
})
Denn diese Abfrage enthält den $regex:
{ "_id" : 2, "first_name" : "Michael", "last_name" : "Hughes", "dept" : "Security" }
{ "_id" : 4, "first_name" : "MICHAEL", "last_name" : "FLORES", "dept" : "Sales" }
Obwohl diese Abfrage die gewünschten Dokumente zurückgibt, sind Regex-Abfragen ohne Berücksichtigung der Groß-/Kleinschreibung ohne Indexunterstützung langsam. Sie können die Effizienz steigern, indem Sie einen Index ohne Berücksichtigung der Groß-/Kleinschreibung für das Feld first_name erstellen.
db.employees.createIndex(
{ first_name: 1 },
{ collation: { locale: 'en', strength: 2 } }
)
Wenn das strength-Feld eines collation-Dokuments eines Indexes auf 1 oder 2 gesetzt ist, unterscheidet der Index nicht zwischen Groß- und Kleinschreibung, um eine ausführlichere Erläuterung des Collation-Dokuments und der verschiedenen Stärke-Werte zu erhalten.
Damit die Anwendung diesen Index verwenden kann, müssen Sie auch das Vergleichsdokument des Index in der Abfrage angeben. Entfernen Sie den Operator $regex aus der vorherigen Funktion db.collection.find() und verwenden Sie stattdessen den neu konstruierten Index.
db.employees.find( { first_name: "michael" } ).collation( { locale: 'en', strength: 2 } )
Verwenden Sie nicht den Operator $regex, wenn Sie einen Index ohne Berücksichtigung der Groß-/Kleinschreibung für Ihre Abfrage verwenden. Die $regex-Implementierung unterstützt keine Sortierung und kann keine Indizes ohne Berücksichtigung der Groß-/Kleinschreibung verwenden.
Verwenden Sie Regex in der find()-Methode für die Suche ohne Berücksichtigung der Groß-/Kleinschreibung in MongoDB
Verwenden Sie Regex in der find()-Methode für die Suche ohne Berücksichtigung der Groß-/Kleinschreibung.
Syntax:
db.demo572.find({"yourFieldName" : { `$regex`:/^yourValue$/i}});
Um die obige Syntax zu verstehen, erstellen wir eine Sammlung von Dokumenten.
> db.demo572.insertOne({"CountryName":"US"});{
"acknowledged" : true, "insertedId" : ObjectId("5e915f0e581e9acd78b427f1")
}
> db.demo572.insertOne({"CountryName":"UK"});{
"acknowledged" : true, "insertedId" : ObjectId("5e915f17581e9acd78b427f2")
}
> db.demo572.insertOne({"CountryName":"Us"});{
"acknowledged" : true, "insertedId" : ObjectId("5e915f1b581e9acd78b427f3")
}
> db.demo572.insertOne({"CountryName":"AUS"});{
"acknowledged" : true, "insertedId" : ObjectId("5e915f20581e9acd78b427f4")
}
> db.demo572.insertOne({"CountryName":"us"});{
"acknowledged" : true, "insertedId" : ObjectId("5e915f25581e9acd78b427f5")
}
Die Funktion find() zeigt alle Dokumente einer Sammlung an.
db.demo572.find();
Dies erzeugt die folgende Ausgabe.
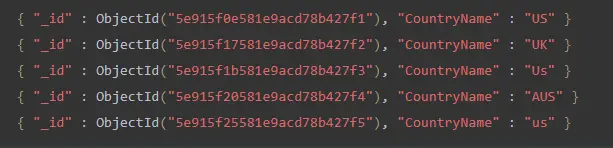
Das Folgende ist die Abfrage für die Suche ohne Berücksichtigung der Groß-/Kleinschreibung.
> db.demo572.find({"CountryName" : { `$regex`:/^US$/i}});
Dies erzeugt die folgende Ausgabe.
