MongoDB의 대소문자를 구분하지 않는 쿼리
- MongoDB의 대소문자를 구분하지 않는 쿼리
- 대소문자를 구분하지 않는 Regex 쿼리 개선
-
MongoDB에서 대소문자를 구분하지 않는 검색을 위해
find()메서드에서 Regex 사용

이 문서에서는 대소문자를 구분하지 않는 쿼리에 대해 간략하게 자세히 설명합니다. 또한 대소문자를 구분하지 않는 검색 쿼리도 자세히 설명합니다.
이 문서에서는 다음 항목에 대해 설명합니다.
- 대소문자를 구분하지 않는 쿼리
- 대소문자를 구분하지 않는 정규식 쿼리 개선
- 대소문자를 구분하지 않는 검색을 위해
find()메서드에서 정규식을 사용합니다.
MongoDB의 대소문자를 구분하지 않는 쿼리
대소문자를 구분하지 않는 인덱스를 사용하면 대소문자를 구분하지 않고 문자열을 비교하는 검색이 가능합니다.
db.collection.createIndex()를 사용하면 collation 매개변수를 선택적 매개변수로 포함하여 대소문자를 구분하지 않는 인덱스를 설정할 수 있습니다.
db.collection.createIndex( { "key" : 1 },
{ collation: {
locale : <locale>,
strength : <strength>
}
} )
대소문자 구분 인덱스에 대한 데이터 정렬을 지정할 때 다음을 포함하십시오.
locale- 언어 규칙을 지정합니다.강도- 비교 규칙을 결정하는 데 사용됩니다.1또는2값은 대소문자를 구분하지 않는 데이터 정렬을 나타냅니다.
행동:
대소문자를 구분하지 않는 인덱스를 사용해도 쿼리 결과에 영향을 미치지 않습니다. 그러나 속도를 향상시킬 수 있습니다.
콜레이션 지정 인덱스를 활용하려면 쿼리 및 정렬 작업에서 인덱스와 동일한 콜레이션을 사용해야 합니다. 컬렉션이 데이터 정렬을 정의하는 경우 해당 컬렉션을 사용하는 모든 쿼리와 인덱스는 다른 데이터 정렬을 지정하지 않는 한 컬렉션을 상속합니다.
대소문자를 구분하지 않는 인덱스 생성
데이터 정렬이 있는 인덱스를 생성하고 strength 옵션을 1 또는 2로 지정하여 기본 데이터 정렬이 없는 컬렉션에서 대소문자를 구분하지 않는 인덱스를 활용합니다. 인덱스 수준 데이터 정렬을 활용하려면 쿼리 수준에서 동일한 데이터 정렬을 제공해야 합니다.
다음 예에서는 기본 데이터 정렬이 없는 컬렉션을 생성하고 대/소문자를 구분하지 않는 데이터 정렬이 있는 인덱스를 type 열에 추가합니다.
db.createCollection("fruit")
db.fruit.createIndex( { type: 1},
{ collation: { locale: `en`, strength: 2 } } )
인덱스를 사용하려면 쿼리에 동일한 데이터 정렬이 있어야 합니다.
db.fruit.insertMany( [
{ type: "bloctak" },
{ type: "Bloctak" },
{ type: "BLOCTAK" }
] )
db.fruit.find( { type: "bloctak" } )
//not use index, finds one result
db.fruit.find( { type: "bloctak" } ).collation( { locale: `en`, strength: 2 } )
// uses index, and will find three results
db.fruit.find( { type: "bloctak" } ).collation( { locale: `en`, strength: 1 } )
//not uses the index, finds three results
기본 데이터 정렬이 있는 컬렉션의 대소문자를 구분하지 않는 인덱스
기본 데이터 정렬로 컬렉션을 설정하면 다른 데이터 정렬을 제공하지 않는 한 이후의 모든 인덱스는 해당 데이터 정렬을 상속합니다. 데이터 정렬을 지정하지 않은 모든 쿼리는 기본 데이터 정렬을 상속합니다.
아래 예제는 기본 데이터 정렬을 사용하여 names 컬렉션을 생성한 다음 first_name 필드를 인덱싱합니다.
db.createCollection("names", { collation: { locale: `en_US`, strength: 2 } } )
db.names.createIndex( { first_name: 1 } ) // inherits the default collation
작은 이름 모음을 삽입합니다.
db.names.insertMany( [
{ first_name: "Betsy" },
{ first_name: "BETSY"},
{ first_name: "betsy"}
] )
이 컬렉션에 대한 쿼리는 기본적으로 제공된 데이터 정렬과 가능한 경우 인덱스를 활용합니다.
db.names.find( { first_name: "betsy" } )
// inherits the default collation: { collation: { locale: `en_US`, strength: 2 } }
// finds three results
앞의 절차에서는 컬렉션의 기본 데이터 정렬을 사용하여 세 문서를 모두 검색합니다. 효율성 향상을 위해 first_name 필드에 인덱스를 사용합니다.
이 컬렉션은 쿼리에서 다른 데이터 정렬을 지정하여 대/소문자 구분 검색을 계속 수행할 수 있습니다.
db.names.find( { first_name: "betsy" } ).collation( { locale: `en_US` } )
// not use the collection`s default collation, finds one result
앞의 절차는 strength 값이 제공되지 않은 데이터 정렬을 사용하기 때문에 하나의 문서만 반환합니다. 인덱스 또는 컬렉션의 기본 데이터 정렬을 사용하지 않습니다.
대소문자를 구분하지 않는 Regex 쿼리 개선
대소문자를 구분하지 않는 정규식 쿼리(I 옵션 사용)를 자주 수행하는 경우 검색을 수용할 수 있도록 대소문자를 구분하지 않는 인덱스를 설정해야 합니다.
인덱스의 데이터 정렬을 사용하여 대소문자 및 악센트 표시 규칙과 같은 언어별 문자열 비교 규칙을 제공할 수 있습니다. 대소문자를 구분하지 않는 인덱스는 대소문자를 구분하지 않는 쿼리의 성능을 크게 향상시킵니다.
직원 컬렉션에서 다음 문서를 고려하십시오. 일반적인 _id 인덱스 외에 이 컬렉션에는 다른 인덱스가 포함되어 있지 않습니다.
db={
"employees": [
{
"_id": 1,
"first_name": "Hannah",
"last_name": "Simmons",
"dept": "Engineering"
},
{
"_id": 2,
"first_name": "Michael",
"last_name": "Hughes",
"dept": "Security"
},
{
"_id": 3,
"first_name": "Wendy",
"last_name": "Crawford",
"dept": "Human Resources"
},
{
"_id": 4,
"first_name": "MICHAEL",
"last_name": "FLORES",
"dept": "Sales"
}
]
}
애플리케이션이 first_name 열을 자주 검색하는 경우 대소문자를 구분하지 않는 정규식 쿼리를 사용하여 일치하는 이름을 찾을 수 있습니다.
대소문자를 구분하지 않는 정규식은 위의 예에서와 같이 Michael과 MICHAEL의 first_name이 모두 다른 데이터 형식과 일치하는 데 도움이 됩니다.
사용자가 michael을 검색하면 프로그램은 다음 쿼리를 실행할 수 있습니다.
db.employees.find({
first_name: {
$regex: "michael",
$options: "i"
}
})
이 쿼리에는 $regex가 포함되어 있기 때문에:
{ "_id" : 2, "first_name" : "Michael", "last_name" : "Hughes", "dept" : "Security" }
{ "_id" : 4, "first_name" : "MICHAEL", "last_name" : "FLORES", "dept" : "Sales" }
이 쿼리는 원하는 문서를 반환하지만 인덱스 지원 없이 대/소문자를 구분하지 않는 정규식 쿼리는 느립니다. first_name 필드에 대소문자를 구분하지 않는 인덱스를 생성하여 효율성을 높일 수 있습니다.
db.employees.createIndex(
{ first_name: 1 },
{ collation: { locale: 'en', strength: 2 } }
)
색인의 collation 문서의 strength 필드가 1 또는 2로 설정되면 색인은 대조 문서 및 다양한 strength 값에 대한 보다 광범위한 설명을 위해 대소문자를 구분하지 않습니다.
애플리케이션이 이 인덱스를 사용하려면 쿼리에서 인덱스의 데이터 정렬 문서도 언급해야 합니다. 이전 db.collection.find() 함수에서 $regex 연산자를 제거하고 대신 새로 구성된 인덱스를 사용합니다.
db.employees.find( { first_name: "michael" } ).collation( { locale: 'en', strength: 2 } )
쿼리에 대해 대소문자를 구분하지 않는 인덱스를 사용할 때 $regex 연산자를 사용하지 마십시오. $regex 구현은 데이터 정렬을 지원하지 않으며 대소문자를 구분하지 않는 인덱스를 사용할 수 없습니다.
MongoDB에서 대소문자를 구분하지 않는 검색을 위해 find() 메서드에서 Regex 사용
대소문자를 구분하지 않는 검색을 위해 find() 메소드에서 정규식을 사용하십시오.
통사론:
db.demo572.find({"yourFieldName" : { `$regex`:/^yourValue$/i}});
위 구문을 이해하기 위해 문서 모음을 만들어 보겠습니다.
> db.demo572.insertOne({"CountryName":"US"});{
"acknowledged" : true, "insertedId" : ObjectId("5e915f0e581e9acd78b427f1")
}
> db.demo572.insertOne({"CountryName":"UK"});{
"acknowledged" : true, "insertedId" : ObjectId("5e915f17581e9acd78b427f2")
}
> db.demo572.insertOne({"CountryName":"Us"});{
"acknowledged" : true, "insertedId" : ObjectId("5e915f1b581e9acd78b427f3")
}
> db.demo572.insertOne({"CountryName":"AUS"});{
"acknowledged" : true, "insertedId" : ObjectId("5e915f20581e9acd78b427f4")
}
> db.demo572.insertOne({"CountryName":"us"});{
"acknowledged" : true, "insertedId" : ObjectId("5e915f25581e9acd78b427f5")
}
find() 기능은 컬렉션의 모든 문서를 표시합니다.
db.demo572.find();
그러면 다음과 같은 출력이 생성됩니다.
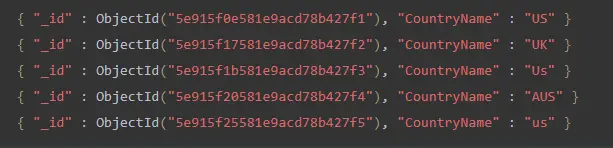
다음은 대소문자를 구분하지 않는 검색을 위한 쿼리입니다.
> db.demo572.find({"CountryName" : { `$regex`:/^US$/i}});
그러면 다음과 같은 출력이 생성됩니다.
