Pandas DataFrame DataFrame.to_excel() Funktion
-
Syntax von
pandas.DataFrame.to_excel() -
Beispiel-Codes: Pandas
DataFrame.to_excel() -
Beispiel-Codes: Pandas
DataFrame.to_excel()mitExcelWriter -
Beispiel-Codes: Pandas
DataFrame.to_excelzum Anhängen an eine bestehende Excel-Datei -
Beispiel-Codes: Pandas
DataFrame.to_excel, um mehrere Blätter zu schreiben -
Beispiel-Codes: Pandas
DataFrame.to_excelmitheader-Parameter -
Beispiel-Codes: Pandas
DataFrame.to_excelmitindex=False -
Beispiel-Codes: Pandas
DataFrame.to_excelmitindex_labelParameter -
Beispiel-Codes: Pandas
DataFrame.to_excelmitfloat_formatParameter -
Beispiel-Codes: Pandas
DataFrame.to_excelmitfreeze_panesParameter
Die Funktion Python Pandas DataFrame.to_excel(values) dumpt die Daten des DataFrame in eine Excel-Datei, in einem einzelnen Blatt oder in mehreren Blättern.
Syntax von pandas.DataFrame.to_excel()
DataFrame.isin(
excel_writer,
sheet_name="Sheet1",
na_rep="",
float_format=None,
columns=None,
header=True,
index=True,
index_label=None,
startrow=0,
startcol=0,
engine=None,
merge_cells=True,
encoding=None,
inf_rep="inf",
verbose=True,
freeze_panes=None,
)
Parameter
excel_writer |
Excel-Dateipfad oder den vorhandenen pandas.ExcelWriter |
sheet_name |
Blattname, auf den der DataFrame ausgegeben wird |
na_rep |
Darstellung von Nullwerten. |
float_format |
Format von Gleitkommazahlen |
header |
Geben Sie den Header der generierten Excel-Datei an. |
index |
Wenn True, schreiben Sie den DataFrame Index in das Excel. |
index_label |
Spaltenbeschriftung für die Indexspalte. |
startrow |
Die obere linke Zellzeile zum Schreiben der Daten in Excel. Standard ist 0 |
startcol |
Die obere linke Zellspalte zum Schreiben der Daten in das Excel. Standard ist 0 |
engine |
Optionaler Parameter zur Angabe der zu verwendenden Engine. openyxl oder xlswriter |
merge_cells |
MultiIndex zu verschmolzenen Zellen verschmelzen |
encoding |
Kodierung der ausgegebenen Excel-Datei. Nur notwendig, wenn xlwt writer verwendet wird, andere Writer unterstützen Unicode nativ. |
inf_rep |
Darstellung der Unendlichkeit. Voreinstellung ist inf. |
verbose |
Wenn True, bestehen Fehlerprotokolle aus mehr Informationen |
freeze_panes |
Geben Sie den untersten und den rechten Rand des eingefrorenen Fensters an. Es ist einbasiert, aber nicht nullbasiert. |
Zurück zu
None
Beispiel-Codes: Pandas DataFrame.to_excel()
import pandas as pd
dataframe= pd.DataFrame({'Attendance': [60, 100, 80, 78, 95],
'Name': ['Olivia', 'John', 'Laura', 'Ben', 'Kevin'],
'Marks': [90, 75, 82, 64, 45]})
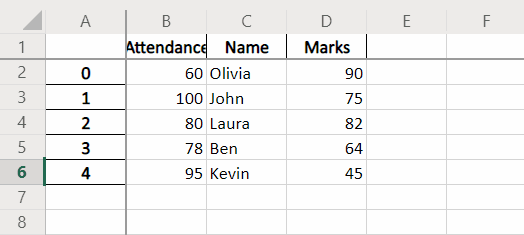
dataframe.to_excel('test.xlsx')
Der Aufrufer DataFrame ist:
Attendance Name Marks
0 60 Olivia 90
1 100 John 75
2 80 Laura 82
3 78 Ben 64
4 95 Kevin 45
test.xlsx wird erstellt.

Beispiel-Codes: Pandas DataFrame.to_excel() mit ExcelWriter
Das obige Beispiel verwendet den Dateipfad als excel_writer, und wir könnten auch pandas.Excelwriter verwenden, um die Excel-Datei anzugeben, die die Datenframe-Dumps erzeugt.
import pandas as pd
dataframe = pd.DataFrame(
{
"Attendance": [60, 100, 80, 78, 95],
"Name": ["Olivia", "John", "Laura", "Ben", "Kevin"],
"Marks": [90, 75, 82, 64, 45],
}
)
with pd.ExcelWriter("test.xlsx") as writer:
dataframe.to_excel(writer)
Beispiel-Codes: Pandas DataFrame.to_excel zum Anhängen an eine bestehende Excel-Datei
import pandas as pd
import openpyxl
dataframe = pd.DataFrame(
{
"Attendance": [60, 100, 80, 78, 95],
"Name": ["Olivia", "John", "Laura", "Ben", "Kevin"],
"Marks": [90, 75, 82, 64, 45],
}
)
with pd.ExcelWriter("test.xlsx", mode="a", engine="openpyxl") as writer:
dataframe.to_excel(writer, sheet_name="new")
Wir sollten die Engine als openpyxl angeben, aber nicht standardmäßig xlsxwriter; andernfalls erhalten wir den Fehler, dass xlswriter den append-Modus nicht unterstützt.
ValueError: Append mode is not supported with xlsxwriter!
openpyxl soll installiert und importiert werden, weil es nicht Teil von pandas ist.
pip install openpyxl
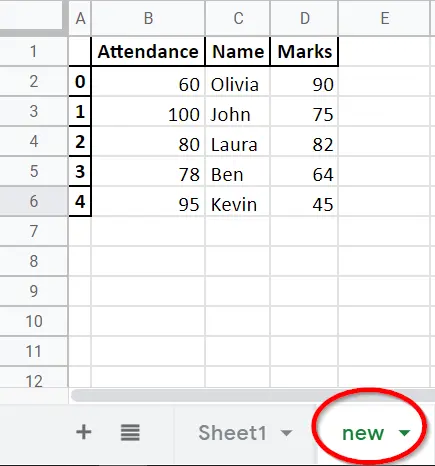
Beispiel-Codes: Pandas DataFrame.to_excel, um mehrere Blätter zu schreiben
import pandas as pd
dataframe = pd.DataFrame(
{
"Attendance": [60, 100, 80, 78, 95],
"Name": ["Olivia", "John", "Laura", "Ben", "Kevin"],
"Marks": [90, 75, 82, 64, 45],
}
)
with pd.ExcelWriter("test.xlsx") as writer:
dataframe.to_excel(writer, sheet_name="Sheet1")
dataframe.to_excel(writer, sheet_name="Sheet2")
Das DataFrameobjekt wird sowohl in Sheet1 als auch in Sheet2 abgelegt.
Sie können auch unterschiedliche Daten in mehrere Blätter schreiben, wenn Sie den Parameter columns angeben.
import pandas as pd
dataframe = pd.DataFrame(
{
"Attendance": [60, 100, 80, 78, 95],
"Name": ["Olivia", "John", "Laura", "Ben", "Kevin"],
"Marks": [90, 75, 82, 64, 45],
}
)
with pd.ExcelWriter("test.xlsx") as writer:
dataframe.to_excel(writer, columns=["Name", "Attendance"], sheet_name="Sheet1")
dataframe.to_excel(writer, columns=["Name", "Marks"], sheet_name="Sheet2")
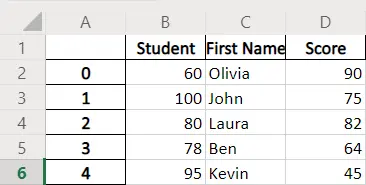
Beispiel-Codes: Pandas DataFrame.to_excel mit header-Parameter
import pandas as pd
dataframe = pd.DataFrame(
{
"Attendance": [60, 100, 80, 78, 95],
"Name": ["Olivia", "John", "Laura", "Ben", "Kevin"],
"Marks": [90, 75, 82, 64, 45],
}
)
with pd.ExcelWriter("test.xlsx") as writer:
dataframe.to_excel(writer, header=["Student", "First Name", "Score"])
Die Standardüberschrift in der erstellten Excel-Datei entspricht den Spaltennamen des DataFrame. Der Parameter header gibt die neue Kopfzeile an, die die Standard-Kopfzeile ersetzen soll.
Beispiel-Codes: Pandas DataFrame.to_excel mit index=False
import pandas as pd
dataframe = pd.DataFrame(
{
"Attendance": [60, 100, 80, 78, 95],
"Name": ["Olivia", "John", "Laura", "Ben", "Kevin"],
"Marks": [90, 75, 82, 64, 45],
}
)
with pd.ExcelWriter("test.xlsx") as writer:
dataframe.to_excel(writer, index=False)
index = False gibt an, dass DataFrame.to_excel() eine Excel-Datei ohne Kopfzeile erzeugt.
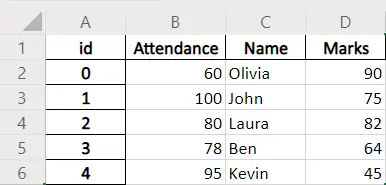
Beispiel-Codes: Pandas DataFrame.to_excel mit index_label Parameter
import pandas as pd
dataframe = pd.DataFrame(
{
"Attendance": [60, 100, 80, 78, 95],
"Name": ["Olivia", "John", "Laura", "Ben", "Kevin"],
"Marks": [90, 75, 82, 64, 45],
}
)
with pd.ExcelWriter("test.xlsx") as writer:
dataframe.to_excel(writer, index_label="id")
index_label='id' setzt den Spaltennamen der Indexspalte auf id.
Beispiel-Codes: Pandas DataFrame.to_excel mit float_format Parameter
import pandas as pd
dataframe = pd.DataFrame(
{
"Attendance": [60, 100, 80, 78, 95],
"Name": ["Olivia", "John", "Laura", "Ben", "Kevin"],
"Marks": [90, 75, 82, 64, 45],
}
)
with pd.ExcelWriter("test.xlsx") as writer:
dataframe.to_excel(writer, float_format="%.1f")
float_format="%.1f" gibt die Gleitkommazahl mit zwei Gleitkommazahlen an.
Beispiel-Codes: Pandas DataFrame.to_excel mit freeze_panes Parameter
import pandas as pd
dataframe = pd.DataFrame(
{
"Attendance": [60, 100, 80, 78, 95],
"Name": ["Olivia", "John", "Laura", "Ben", "Kevin"],
"Marks": [90, 75, 82, 64, 45],
}
)
with pd.ExcelWriter("test.xlsx") as writer:
dataframe.to_excel(writer, freeze_panes=(1, 1))
freeze_panes=(1,1) gibt an, dass die Excel-Datei die oberste Zeile und die erste Spalte eingefroren hat.

Founder of DelftStack.com. Jinku has worked in the robotics and automotive industries for over 8 years. He sharpened his coding skills when he needed to do the automatic testing, data collection from remote servers and report creation from the endurance test. He is from an electrical/electronics engineering background but has expanded his interest to embedded electronics, embedded programming and front-/back-end programming.
LinkedIn Facebook