在 OpenCV 中使用 OCR 从图像中提取文本

本文将介绍开始使用光学字符识别(也称为 OCR)所需的一切。你将学习如何在 OpenCV 中从图像中提取文本并在图像上可视化提取的文本。
使用带有 EasyOCR 库的 OCR 从 OpenCV 中的图像中提取文本
在本文中,我们需要做四件关键的事情:
-
我们需要安装和导入我们的依赖项。
-
然后,我们需要阅读我们的图像或视频。
-
接下来,我们将绘制我们的结果。
-
最后,我们将使用 OpenCV 来了解如何处理具有多行文本的图像并将它们可视化。
光学字符识别,也称为 OCR,可识别图像中的文本。它将严格的手写或打印文本转换为机器可读的格式。
许多行业将 OCR 技术用于自动化银行业务;可以使用 OCR 处理手写支票。OCR 的另一个重要应用是从手写文档中提取信息。
我们将使用 EasyOCR 库来使用由 PyTorch 库提供支持的 OCR。该库使在图像或文档上进行光学字符识别和执行光学字符识别变得更加容易。
让我们开始安装并导入我们的依赖项。我们需要安装的第一个依赖项是 PyTorch,因为 EasyOCR 在 PyTorch 上运行。
这取决于用户正在运行什么类型的操作系统以及是否使用 GPU。安装可能略有不同,但好在如果用户去 python.org,它会自动为用户选择最佳的安装方法类型。
运行以下命令安装 EasyOCR 包:
pip install easyocr
现在我们准备好使用依赖项了。
import easyocr
import cv2
import matplotlib.pyplot as plot
import numpy as np
现在我们需要阅读我们的图像。我们将包含一个变量来保存该图像路径,接下来是使用 EasyOCR 来执行该光学字符识别。
我们定义了 easyocr.Reader() 类,并将我们想要使用的语言传递给它。如果我们不使用 GPU,我们将设置 gpu 参数等于 False。
在下一行中,我们定义了 reader.readtext() 方法并传递了我们的图像路径。
IMG_P = "sign.png"
reader = easyocr.Reader(["en"])
RST = reader.readtext(IMG_P)
RST
当我们运行这段代码时,它的结果会返回一些不同的东西。

我们得到了一个数组,其中文本在我们的图像中,当我们将其可视化时,我们将能够更好地看到这一点。第二部分是识别的文本,最后是置信度。
让我们可视化结果,为此,我们需要定义几个关键变量来识别我们不同坐标的位置。我们将获取左上角和右下角的值来获取和定义坐标。
我们将从数组中定义索引以获取组件值并将它们转换为元组,因为当将其传递给 OpenCV 时,它需要一个元组作为参数。
我们将做类似的事情来抓取右下角和文本,但我们不需要将文本转换为元组。
T_LEFT = tuple(RST[0][0][0])
B_RIGHT = tuple(RST[0][0][2])
text = RST[0][1]
font = cv2.FONT_HERSHEY_SIMPLEX
现在我们使用 imread() 方法来读取我们的图像,在下一行中,我们覆盖了作为组件的矩形,然后我们覆盖了文本以绘制我们的矩形。
rectangle() 方法将第一个参数作为图像。我们传递的下一个参数是 T_LEFT 坐标,下一个是 B_RIGHT 坐标。
传递的下一个参数是一个元组,然后是亮绿色。我们还通过了矩形厚度。
我们使用带有多个参数的 putText() 方法来可视化文本。第一个是图像坐标,我们要设置提取文本的位置、字体样式和字体大小,下一个是颜色、粗细和线条样式。
import easyocr
import cv2
import matplotlib.pyplot as plot
import numpy as np
IMG_P = "surf.jpeg"
reader = easyocr.Reader(["en"])
RST = reader.readtext(IMG_P)
RST
T_LEFT = tuple(RST[0][0][0])
B_RIGHT = tuple(RST[0][0][2])
text = RST[0][1]
font = cv2.FONT_HERSHEY_SIMPLEX
IMG = cv2.imread("surf.jpeg")
IMG = cv2.rectangle(IMG, T_LEFT, B_RIGHT, (0, 255, 0), 3)
IMG = cv2.putText(IMG, text, T_LEFT, font, 0.5, (255, 255, 255), 2, cv2.LINE_AA)
plot.imshow(IMG)
plot.show()
我们可以看到在文本周围绘制了一个框,并且 surf 出现在矩形内。

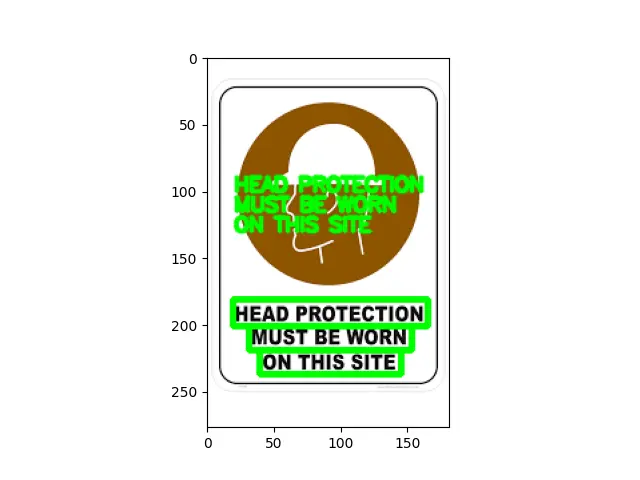
让我们看看如果我们有一个包含多行文本的图像如何处理。几乎是一样的;唯一改变的是当我们打印结果时,我们会看到几个不同的行。
因此,我们需要循环以单独可视化和绘制每个检测。
import easyocr
import cv2
import matplotlib.pyplot as plot
import numpy as np
IMG_P = "sign.png"
reader = easyocr.Reader(["en"])
RST = reader.readtext(IMG_P)
RST
font = cv2.FONT_HERSHEY_SIMPLEX
IMG = cv2.imread(IMG_P)
spacer = 100
for detection in RST:
T_LEFT = tuple(detection[0][0])
B_RIGHT = tuple(detection[0][2])
TEXT = detection[1]
IMG = cv2.rectangle(IMG, T_LEFT, B_RIGHT, (0, 255, 0), 3)
IMG = cv2.putText(IMG, TEXT, (20, spacer), font, 0.5, (0, 255, 0), 2, cv2.LINE_AA)
spacer += 15
plot.imshow(IMG)
plot.show()
输出:

Hello! I am Salman Bin Mehmood(Baum), a software developer and I help organizations, address complex problems. My expertise lies within back-end, data science and machine learning. I am a lifelong learner, currently working on metaverse, and enrolled in a course building an AI application with python. I love solving problems and developing bug-free software for people. I write content related to python and hot Technologies.
LinkedIn