OpenCV 物件檢測

本教程將討論使用 OpenCV 中的級聯分類器和 YOLO 檢測影象或視訊流中的物件。
在 OpenCV 中使用級聯分類器進行物件檢測
我們可以檢測影象中存在的物件,例如人臉、動物臉、眼睛等。我們可以使用 OpenCV 的 CascadeClassifier 類來檢測影象中存在的物件。
級聯分類器使用 Haar 特徵來使用級聯特徵檢測物件。我們必須使用經過訓練的模型,其中包含我們想要在影象中檢測到的物件的特徵。
OpenCV 有許多基於 Haar 特徵的預訓練模型。該演算法從輸入影象中生成視窗,然後將它們與特徵集進行比較。
單個預訓練模型包含大約 160,000 個特徵,將視窗與每個特徵進行比較需要大量時間。
所以演算法從特徵中進行級聯,如果一個視窗與第一個級聯匹配,它將與第二個級聯進行比較;否則,它將被丟棄。
這樣,演算法將花費更少的時間來檢測物體。例如,讓我們使用包含貓和人的影象和級聯分類器來檢測影象中存在的眼睛。
請參閱下面的程式碼。
import cv2
src_img = cv2.imread("animal.jpg")
gray_img = cv2.cvtColor(src_img, cv2.COLOR_BGR2GRAY)
c_classifier = cv2.CascadeClassifier(f"{cv2.data.haarcascades}haarcascade_eye.xml")
d_objects = c_classifier.detectMultiScale(gray_img, minSize=(50, 50))
if len(d_objects) != 0:
for (x, y, h, w) in d_objects:
cv2.rectangle(src_img, (x, y), ((x + h), (y + w)), (0, 255, 255), 5)
cv2.imshow("Detected Objects", src_img)
cv2.waitKey(0)
cv2.destroyAllWindows()
輸出:

在上面的程式碼中,我們使用預訓練模型 haarcascade_eye.xml 進行眼睛檢測,但我們可以使用許多其他預訓練模型,例如面部、微笑和身體檢測。預訓練模型儲存在 OpenCV 的資料資料夾中,也可以在此連結中找到它們。
我們使用級聯分類器的 detectMultiScale() 函式來檢測物件。該函式將為每個物件返回一個向量,其中包含 x 和 y 座標以及檢測到的物件的寬度和高度。
我們可以使用此輸出在檢測到的物件周圍繪製一個形狀,例如矩形或圓形。
detectMultiScale() 函式的第一個引數是灰度輸入影象。第二個引數 minSize 用於設定我們想要檢測的物件的最小尺寸。
我們還可以在 detectMultiScale() 函式中設定其他可選引數。第一個可選引數是 scaleFactor,用於設定影象比例,預設設定為 1.1。
第二個可選引數是 minNeighbors,它用於設定用於物件檢測的最小鄰居數,預設情況下,其值設定為 3。第三個可選引數是 maxSize,它設定我們想要檢測的物件的最大尺寸。
我們使用 OpenCV 的 rectangle() 函式在檢測到的物件周圍繪製一個矩形。第一個引數是我們要在其上繪製矩形的影象。
第二個和第三個引數是矩形的開始和結束位置。第四個引數用於定義 BGR 色標中的顏色,第五個引數用於設定矩形的線寬。
預訓練的模型大多包含面部特徵,但我們也可以製作我們的模型用於物件檢測。檢視此連結瞭解有關級聯分類器模型訓練的更多詳細資訊。
在 OpenCV 中使用 YOLO 進行目標檢測
多個檢測器被用於物件檢測,如單次檢測器、RNN 和快速 RNN。與其他檢測器相比,單次檢測器速度快,但精度較低。
YOLO 就像一個單次檢測器,與單次檢測器相比速度快但與單次檢測器具有相同的精度。YOLO 將整個影象通過深度神經網路來檢測影象或視訊中存在的物件。
該演算法找到影象中存在的物件周圍的邊界框及其置信度,並根據置信度過濾框。如果某個框的置信度低於特定值,則該框將被丟棄。
YOLO 還使用非最大抑制技術來消除單個物件周圍的重疊邊界框。這樣,我們只會得到一個圍繞一個物件的邊界框。
YOLO 為深度神經網路預訓練了權重和配置,我們可以使用 OpenCV 的 dnn.readNetFromDarknet() 函式載入它們。我們還可以獲取 COCO 資料集中存在的不同物件的類名。
我們必須下載 weights、configurations 和 COCO 名稱檔案才能在 OpenCV 中使用它們。我們可以使用 COCO 名稱將物件的名稱放在邊界框上。
載入資料後,我們必須讀取影象並使用 dnn.blobFromImage() 函式建立一個 blob,然後我們可以使用 setInput() 函式將其傳遞到深度神經網路。
我們可以使用 setPreferableBackend() 函式將神經網路的首選後端設定為 OpenCV。我們還可以使用 setPreferableTarget() 函式將首選目標設定為 CPU 或 GPU。
如果我們有 GPU,YOLO 會比 CPU 執行得更快。我們必須執行網路直到最後一層,我們可以使用 getLayerNames() 函式來查詢層名稱和 getUnconnectedOutLayers() 函式來獲取最後一層。
現在我們將使用一個迴圈來查詢邊界框及其置信度,如果置信度低於特定值,則丟棄該框,並儲存其他框。
之後,我們將使用 dnn.NMSBoxes() 函式使用非最大抑制技術過濾框。
dnn.NMSBoxes() 函式將返回我們的 x 和 y 座標以及邊界框的寬度和高度,我們可以將這些值傳遞給 rectangle() 函式以在每個檢測到的物件周圍繪製一個矩形。
我們可以使用 OpenCV 的 putText() 函式將物件名稱放在使用 COCO 名稱的矩形頂部。
例如,讓我們使用影象並使用 YOLO 查詢存在的物件。請參閱下面的程式碼。
import cv2
import numpy as np
img_src = cv2.imread("animal.jpg")
cv2.imshow("window", img_src)
cv2.waitKey(1)
classes_names = open("coco.names").read().strip().split("\n")
np.random.seed(42)
colors_rnd = np.random.randint(0, 255, size=(len(classes_names), 3), dtype="uint8")
net_yolo = cv2.dnn.readNetFromDarknet("yolov3.cfg", "yolov3.weights")
net_yolo.setPreferableBackend(cv2.dnn.DNN_BACKEND_OPENCV)
net_yolo.setPreferableTarget(cv2.dnn.DNN_TARGET_CPU)
ln = net_yolo.getLayerNames()
ln = [ln[i - 1] for i in net_yolo.getUnconnectedOutLayers()]
blob_img = cv2.dnn.blobFromImage(
img_src, 1 / 255.0, (416, 416), swapRB=True, crop=False
)
r_blob = blob_img[0, 0, :, :]
cv2.imshow("blob", r_blob)
text = f"Blob shape={blob_img.shape}"
net_yolo.setInput(blob_img)
outputs = net_yolo.forward(ln)
boxes = []
confidences = []
classIDs = []
h, w = img_src.shape[:2]
for output in outputs:
for detection in output:
scores_yolo = detection[5:]
classID = np.argmax(scores_yolo)
confidence = scores_yolo[classID]
if confidence > 0.5:
box_rect = detection[:4] * np.array([w, h, w, h])
(centerX, centerY, width, height) = box_rect.astype("int")
x_c = int(centerX - (width / 2))
y_c = int(centerY - (height / 2))
box_rect = [x_c, y_c, int(width), int(height)]
boxes.append(box_rect)
confidences.append(float(confidence))
classIDs.append(classID)
indices_yolo = cv2.dnn.NMSBoxes(boxes, confidences, 0.5, 0.4)
if len(indices_yolo) > 0:
for i in indices_yolo.flatten():
(x, y) = (boxes[i][0], boxes[i][1])
(w, h) = (boxes[i][2], boxes[i][3])
color = [int(c) for c in colors_rnd[classIDs[i]]]
cv2.rectangle(img_src, (x, y), (x + w, y + h), color, 3)
text = "{}: {:.4f}".format(classes_names[classIDs[i]], confidences[i])
cv2.putText(img_src, text, (x, y - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.6, color, 2)
cv2.imshow("window", img_src)
cv2.waitKey(0)
cv2.destroyAllWindows()
輸出:
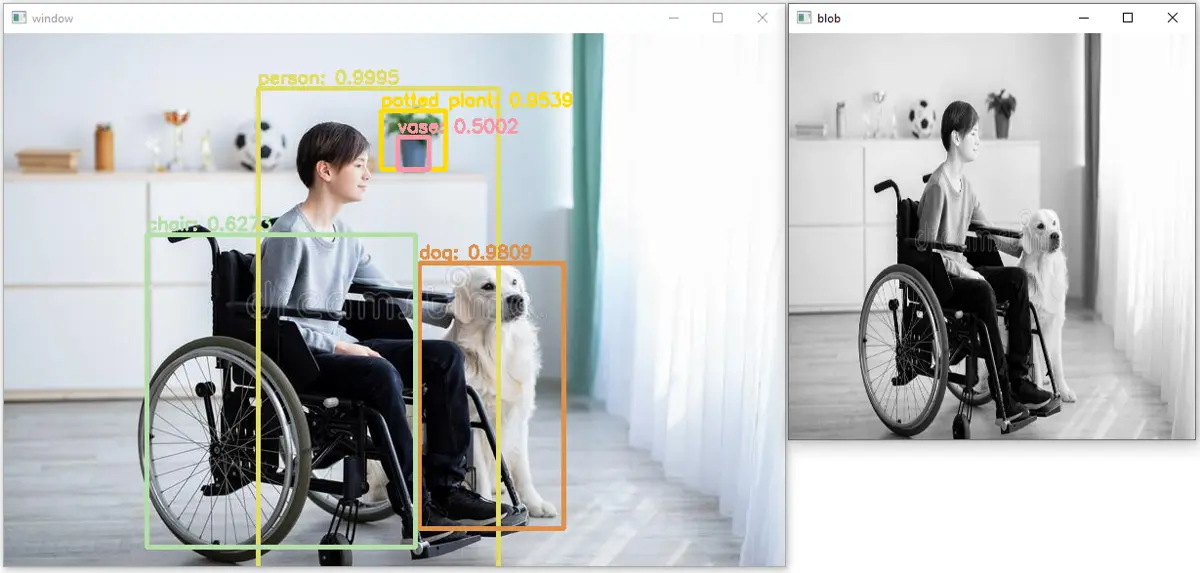
如我們所見,在上圖中已經檢測到五個物件,它們的準確度或置信度也被置於矩形之上。我們也可以將相同的程式碼應用於視訊;我們必須讀取每一幀,在每一幀上應用上面的程式碼,然後再次將幀儲存在視訊中。
在上面的程式碼中,np.random.randint() 函式用於建立隨機顏色。第一個引數是顏色的起始值,第二個引數是顏色的結束值。
第三個引數 size 用於設定每種顏色的大小,第四個引數 dtype 用於設定輸出的資料型別。append() 函式將值新增到給定的陣列中。
OpenCV 的 rectangle() 函式用於在檢測到的物件周圍繪製矩形。第一個引數是我們要在其上繪製矩形的影象。
第二個引數是矩形左上角的起點或位置,第三個引數是矩形的終點或右上角的位置。第四個引數是顏色,第五個引數是矩形的線寬。
putText() 函式用於在影象上放置文字。第一個引數是我們要在其上放置文字的影象,第二個引數是我們要在影象上放置的文字。
第三個引數是文字的起始位置,第四個引數是文字的字型樣式。第五個引數用於設定字型比例,第六個引數用於設定文字的線寬。
