Python의 Fama-Macbeth 회귀
- Fama-Macbeth 회귀 및 그 중요성
- Python에서 Fama-Macbeth 회귀를 구현하는 단계
-
LinearModels를 사용하여 Python에서 Fama-Macbeth 회귀를 구현합니다. - Python에서 Fama-Macbeth 회귀를 구현하기 위한 대체 접근 방식
오늘의 기사에서는 Fama-Macbeth 회귀, 그 중요성 및 구현에 대해 교육합니다.
Fama-Macbeth 회귀 및 그 중요성
자산 가격 이론에서 우리는 위험 요소를 사용하여 자산 수익을 설명합니다. 이러한 위험 요인은 미시경제적이거나 거시경제적일 수 있습니다.
미시경제적 위험 요인에는 기업 규모와 기업의 다양한 재무 지표가 포함되며, 거시경제적 위험 요인에는 소비자 인플레이션과 실업률이 포함됩니다.
Fama-Macbeth 회귀는 자산 가격 모델을 테스트하는 데 사용되는 2단계 회귀 모델입니다. 이러한 위험 요소가 포트폴리오 또는 자산 수익을 얼마나 정확하게 설명하는지 측정하는 것은 실용적인 접근 방식입니다.
이 모델은 이러한 요인에 대한 노출과 관련된 위험 프리미엄을 결정하는 데 유용합니다.
이제 요점은 왜 Fama-Macbeth를 2단계 회귀 모델이라고 부르는가입니다. 아래에서 이러한 단계를 알아 보겠습니다.
- 이 단계는 시계열 접근 방식을 사용하여 하나 이상의 위험 요소에 대해 모든 자산의 수익을 회귀하는 것입니다. 우리는
베타,요인 부하또는요인 노출로 알려진 모든 요인에 대한 수익 노출을 얻습니다. - 이 단계는 횡단면 접근 방식을 사용하여 이전 단계(1단계)에서 획득한 자산
베타에 대한 모든 자산의 수익을 회귀하는 것입니다. 여기에서 우리는 모든 요소에 대한 위험 프리미엄을 얻습니다.
Fama와 Macbeth에 따르면 모든 위험 요소에 대한 단위 노출에 대한 시간 경과에 따른 예상 프리미엄은 모든 요소에 대해 한 번씩 계수를 평균화하여 계산됩니다.
Python에서 Fama-Macbeth 회귀를 구현하는 단계
2018년 가을부터 Fama-Macbeth의 라이브러리 환경을 반영하기 위한 업데이트에 따라 fama_macbeth는 한동안 Python pandas 모듈에서 제거되었습니다.
그렇다면 Python으로 작업하는 경우 Fama-Macbeth를 어떻게 구현할 수 있습니까? 이 자습서에서 하나씩 배울 다음 두 가지 접근 방식이 있습니다.
- Python 버전 3을 사용하는 경우
LinearModels에서fama_macbeth기능을 사용할 수 있습니다. LinearModels를 사용할 필요가 없거나 Python 버전 2를 사용하는 경우 가장 좋은 경우는 Fama-Macbeth용 구현을 작성하는 것입니다.
LinearModels를 사용하여 Python에서 Fama-Macbeth 회귀를 구현합니다.
-
필요한 모듈과 라이브러리를 가져옵니다.
import pandas as pd import numpy as np from pathlib import Path from linearmodels.asset_pricing import LinearFactorModel from statsmodels.api import OLS, add_constant import matplotlib.pyplot as plt import pandas_datareader.data as web import seaborn as sns import warnings warnings.filterwarnings("ignore") sns.set_style("whitegrid")먼저
LinearModels를 사용하여 Fama-Macbeth를 구현하는 데 필요한 모든 모듈과 라이브러리를 가져옵니다. 그들 모두에 대한 간략한 설명은 다음과 같습니다.- 데이터 프레임 작업을 위해
pandas를 가져오고 배열을 위해numpy를 가져옵니다. pathlib는 이 특정 스크립트를Path개체에 배치하여 지정된 파일에 대한 경로를 만듭니다.linearmodels.asset_pricing에서LinearFactorModel을 가져옵니다. 선형 요소 모델은 선형 방정식으로 설명되는 관계와 함께 자산의 수익을 제한된/제한된 수의요인값과 관련시킵니다.- 다음으로
OLS를 가져와서 선형 회귀 모델을 평가하고add_constant를 가져와 배열에 1의 열을 추가합니다.statsmodels여기에 대해 자세히 알아볼 수 있습니다. - 그런 다음
pandas_datareader를 가져와pandas와 함께 사용할 최신 원격 데이터에 액세스합니다. 다양한pandas버전에서 작동합니다. - 데이터 플로팅 및 시각화 목적으로
matplotlib및seaborn라이브러리를 가져옵니다. - 경고를 무시하는
filterwarnings()메서드를 사용하기 위해Warnings를 가져옵니다. - 마지막으로
seaborn모듈의set_style()메서드를 사용하여 플롯의 일반 스타일을 제어하는 매개변수를 설정합니다.
- 데이터 프레임 작업을 위해
-
원격 위험 요인 및 연구 포트폴리오 데이터 세트에 액세스합니다.
ff_research_data_five_factor = "F-F_Research_Data_5_Factors_2x3" ff_factor_dataset = web.DataReader( ff_research_data_five_factor, "famafrench", start="2010", end="2017-12" )[0]여기서는 웹사이트에서 사용할 수 있는 업데이트된 위험 요소 및 연구 포트폴리오 데이터 세트(5가지 Fama-French 요소)를 사용하여 위에서 주어진
2010-2017에 대해 얻은 월별 빈도로 돌아갑니다.DataReader()를 사용하여 지정된 인터넷 리소스에서 코드 펜스의ff_factor_dataset인pandas데이터 프레임으로 데이터를 추출합니다.DataReader()는 예를 들어Tiingo,IEX,Alpha Vantage등 이 페이지에서 읽을 수 있는 다양한 소스를 지원합니다.print("OUTPUT for info(): \n") print(ff_factor_dataset.info())다음으로
info()가 열 수, 열의 데이터 유형, 열 레이블, 범위 인덱스, 메모리를 포함하는 데이터 프레임의 정보를 인쇄하는df.info()및df.describe()메서드를 사용합니다. 사용량 및 모든 열의 셀 수(null이 아닌 값).아래에서
info()에 의해 생성된 출력을 볼 수 있습니다.출력:
OUTPUT for info(): <class 'pandas.core.frame.DataFrame'> PeriodIndex: 96 entries, 2010-01 to 2017-12 Freq: M Data columns (total 6 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Mkt-RF 96 non-null float64 1 SMB 96 non-null float64 2 HML 96 non-null float64 3 RMW 96 non-null float64 4 CMA 96 non-null float64 5 RF 96 non-null float64 dtypes: float64(6) memory usage: 5.2 KB None다음으로
describe()메서드를 다음과 같이 사용합니다.print("OUTPUT for describe(): \n") print(ff_factor_dataset.describe())describe()메서드는 데이터 프레임의 통계 요약을 보여줍니다. Python 시리즈에도 이 방법을 사용할 수 있습니다. 이 통계 요약에는 평균, 중앙값, 개수, 표준 편차, 열의 백분위수 값 및 최소-최대가 포함됩니다.아래에서
describe()메서드의 출력을 찾을 수 있습니다.출력:
OUTPUT for describe(): Mkt-RF SMB HML RMW CMA RF count 96.000000 96.000000 96.000000 96.000000 96.000000 96.000000 mean 1.158438 0.060000 -0.049271 0.129896 0.047708 0.012604 std 3.580012 2.300292 2.202912 1.581930 1.413033 0.022583 min -7.890000 -4.580000 -4.700000 -3.880000 -3.240000 0.000000 25% -0.917500 -1.670000 -1.665000 -1.075000 -0.952500 0.000000 50% 1.235000 0.200000 -0.275000 0.210000 0.010000 0.000000 75% 3.197500 1.582500 1.205000 1.235000 0.930000 0.010000 max 11.350000 7.040000 8.190000 3.480000 3.690000 0.090000 -
17개 산업 포트폴리오에 액세스하고 위험 요인 비율을 뺍니다.
ff_industry_portfolio = "17_Industry_Portfolios" ff_industry_portfolio_dataset = web.DataReader( ff_industry_portfolio, "famafrench", start="2010", end="2017-12" )[0] ff_industry_portfolio_dataset = ff_industry_portfolio_dataset.sub( ff_factor_dataset.RF, axis=0 )여기에서
DataReader()를 사용하여 매월 17개의 산업 포트폴리오 또는 자산에 액세스하고DataReader()가 반환한 데이터 프레임에서무위험비율(RF)을 뺍니다. 왜? 요인 모델이 초과 수익과 함께 작동하기 때문입니다.이제
info()메서드를 사용하여 연결된 데이터 프레임에 대한 정보를 얻습니다.print(ff_industry_portfolio_dataset.info())출력:
<class 'pandas.core.frame.DataFrame'> PeriodIndex: 96 entries, 2010-01 to 2017-12 Freq: M Data columns (total 17 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Food 96 non-null float64 1 Mines 96 non-null float64 2 Oil 96 non-null float64 3 Clths 96 non-null float64 4 Durbl 96 non-null float64 5 Chems 96 non-null float64 6 Cnsum 96 non-null float64 7 Cnstr 96 non-null float64 8 Steel 96 non-null float64 9 FabPr 96 non-null float64 10 Machn 96 non-null float64 11 Cars 96 non-null float64 12 Trans 96 non-null float64 13 Utils 96 non-null float64 14 Rtail 96 non-null float64 15 Finan 96 non-null float64 16 Other 96 non-null float64 dtypes: float64(17) memory usage: 13.5 KB None마찬가지로
describe()메서드를 사용하여 이 데이터 프레임을 설명합니다.print(ff_industry_portfolio_dataset.describe())출력:
Food Mines Oil Clths Durbl Chems \ count 96.000000 96.000000 96.000000 96.000000 96.000000 96.000000 mean 1.046771 0.202917 0.597187 1.395833 1.151458 1.305000 std 2.800555 7.904401 5.480938 5.024408 5.163951 5.594161 min -5.170000 -24.380000 -11.680000 -10.000000 -13.160000 -17.390000 25% -0.785000 -5.840000 -3.117500 -1.865000 -2.100000 -1.445000 50% 0.920000 -0.435000 0.985000 1.160000 1.225000 1.435000 75% 3.187500 5.727500 4.152500 3.857500 4.160000 4.442500 max 6.670000 21.940000 15.940000 17.190000 16.610000 18.370000 Cnsum Cnstr Steel FabPr Machn Cars \ count 96.000000 96.000000 96.000000 96.000000 96.000000 96.000000 mean 1.186979 1.735521 0.559167 1.350521 1.217708 1.279479 std 3.142989 5.243314 7.389679 4.694408 4.798098 5.719351 min -7.150000 -14.160000 -20.490000 -11.960000 -9.070000 -11.650000 25% -0.855000 -2.410000 -4.395000 -1.447500 -2.062500 -1.245000 50% 1.465000 2.175000 0.660000 1.485000 1.525000 0.635000 75% 3.302500 5.557500 4.212500 3.837500 4.580000 4.802500 max 8.260000 15.510000 21.350000 17.660000 14.750000 20.860000 Trans Utils Rtail Finan Other count 96.000000 96.000000 96.000000 96.000000 96.000000 mean 1.463750 0.896458 1.233958 1.248646 1.290938 std 4.143005 3.233107 3.512518 4.839150 3.697608 min -8.560000 -6.990000 -9.180000 -11.140000 -7.890000 25% -0.810000 -0.737500 -0.952500 -1.462500 -1.090000 50% 1.480000 1.240000 0.865000 1.910000 1.660000 75% 4.242500 2.965000 3.370000 4.100000 3.485000 max 12.980000 7.840000 12.440000 13.410000 10.770000 -
초과 수익을 계산합니다.
초과 수익률 계산으로 이동하기 전에 몇 가지 단계를 더 수행해야 합니다.
data_store = Path("./data/assets.h5") wiki_prices_df = pd.read_csv( "./dataset/wiki_prices.csv", parse_dates=["date"], index_col=["date", "ticker"], infer_datetime_format=True, ).sort_index() us_equities_data_df = pd.read_csv("./dataset/us_equities_data.csv") with pd.HDFStore(data_store) as hdf_store: hdf_store.put("quandl/wiki/prices", wiki_prices_df) with pd.HDFStore(data_store) as hdf_store: hdf_store.put("us_equities/stocks", us_equities_data_df.set_index("ticker"))먼저 현재 디렉토리에 있는
data폴더에assets.h5파일을 만듭니다. 다음으로read_csv()메서드를 사용하여 같은 디렉터리에서dataset폴더에 있는wiki_prices.csv및us_equities_data.csv파일을 읽습니다.그런 다음 위에서 주어진
HDFStore()를 사용하여HDF5형식으로 데이터를 저장합니다.with pd.HDFStore("./data/assets.h5") as hdf_store: prices = hdf_store["/quandl/wiki/prices"].adj_close.unstack().loc["2010":"2017"] equities = hdf_store["/us_equities/stocks"].drop_duplicates() sectors = equities.filter(prices.columns, axis=0).sector.to_dict() prices = prices.filter(sectors.keys()).dropna(how="all", axis=1) returns_df = prices.resample("M").last().pct_change().mul(100).to_period("M") returns_df = returns.dropna(how="all").dropna(axis=1) print(returns_df.info())위의 코드 펜스에서 방금
assets.h5파일에 저장한/quandl/wiki/prices및/us_equities/stocks를 읽고prices및equities변수에 저장했습니다.그런 다음
가격및주식에 일부 필터를 적용하고, 리샘플링하고, 누락된 값을 제거합니다. 마지막으로info()메서드를 사용하여 데이터 프레임returns_df의 정보를 인쇄합니다. 아래 출력을 볼 수 있습니다.출력:
<class 'pandas.core.frame.DataFrame'> PeriodIndex: 95 entries, 2010-02 to 2017-12 Freq: M Columns: 1986 entries, A to ZUMZ dtypes: float64(1986) memory usage: 1.4 MB None이제 다음 코드를 실행하여 데이터를 정렬합니다.
ff_factor_dataset = ff_factor_dataset.loc[returns_df.index] ff_industry_portfolio_dataset = ff_industry_portfolio_dataset.loc[returns_df.index] print(ff_factor_dataset.describe())출력:
Mkt-RF SMB HML RMW CMA RF count 95.000000 95.000000 95.000000 95.000000 95.000000 95.000000 mean 1.206000 0.057053 -0.054316 0.144632 0.043368 0.012737 std 3.568382 2.312313 2.214041 1.583685 1.419886 0.022665 min -7.890000 -4.580000 -4.700000 -3.880000 -3.240000 0.000000 25% -0.565000 -1.680000 -1.670000 -0.880000 -0.965000 0.000000 50% 1.290000 0.160000 -0.310000 0.270000 0.010000 0.000000 75% 3.265000 1.605000 1.220000 1.240000 0.940000 0.010000 max 11.350000 7.040000 8.190000 3.480000 3.690000 0.090000이제 초과 수익률을 계산할 준비가 되었습니다.
excess_returns_df = returns_df.sub(ff_factor_dataset.RF, axis=0) excess_returns_df = excess_returns_df.clip( lower=np.percentile(excess_returns_df, 1), upper=np.percentile(excess_returns_df, 99), ) excess_returns_df.info()위의 코드 블록에서는
ff_factor_dataset에서 위험 요소를 빼고 반환된 데이터 프레임을excess_returns_df에 저장합니다.다음으로 지정된 입력 임계값에서 값을 트리밍하는
.clip()메서드를 사용합니다. 마지막으로info()를 사용하여excess_returns_df데이터 프레임의 정보를 출력합니다.출력:
<class 'pandas.core.frame.DataFrame'> PeriodIndex: 95 entries, 2010-02 to 2017-12 Freq: M Columns: 1986 entries, A to ZUMZ dtypes: float64(1986) memory usage: 1.4 MBFama-Macbeth 회귀의 첫 번째 단계로 이동하기 전에 열 또는 행에서 지정된 레이블을 삭제하는
.drop()메서드를 사용합니다.axis=1은 열에서 삭제를 의미하고axis=0은 행에서 삭제를 의미합니다.ff_factor_dataset = ff_factor_dataset.drop("RF", axis=1) print(ff_factor_dataset.info())출력:
<class 'pandas.core.frame.DataFrame'> PeriodIndex: 95 entries, 2010-02 to 2017-12 Freq: M Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Mkt-RF 95 non-null float64 1 SMB 95 non-null float64 2 HML 95 non-null float64 3 RMW 95 non-null float64 4 CMA 95 non-null float64 dtypes: float64(5) memory usage: 4.5 KB None -
Fama-Macbeth 회귀 1단계: 요인 노출을 구현합니다.
betas = [] for industry in ff_industry_portfolio_dataset: step_one = OLS( endog=ff_industry_portfolio_dataset.loc[ff_factor_dataset.index, industry], exog=add_constant(ff_factor_dataset), ).fit() betas.append(step_one.params.drop("const")) betas = pd.DataFrame( betas, columns=ff_factor_dataset.columns, index=ff_industry_portfolio_dataset.columns, ) print(betas.info())위의 코드 스니펫은 Fama-Macbeth 회귀의 첫 번째 단계를 구현하고 17요소 로딩 추정값에 액세스합니다. 여기에서
OLS()를 사용하여 선형 회귀 모델을 평가하고add_constant()를 사용하여 배열에 1의 열을 추가합니다.출력:
<class 'pandas.core.frame.DataFrame'> Index: 17 entries, Food to Other Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Mkt-RF 17 non-null float64 1 SMB 17 non-null float64 2 HML 17 non-null float64 3 RMW 17 non-null float64 4 CMA 17 non-null float64 dtypes: float64(5) memory usage: 1.3+ KB None -
Fama-Macbeth 회귀 2단계: 위험 프리미엄을 구현합니다.
lambdas = [] for period in ff_industry_portfolio_dataset.index: step_two = OLS( endog=ff_industry_portfolio_dataset.loc[period, betas.index], exog=betas ).fit() lambdas.append(step_two.params) lambdas = pd.DataFrame( lambdas, index=ff_industry_portfolio_dataset.index, columns=betas.columns.tolist() ) print(lambdas.info())두 번째 단계에서는 팩터 로딩에 대한 포트폴리오의 단면에 대해
기간수익률의 96회 회귀를 실행합니다.출력:
<class 'pandas.core.frame.DataFrame'> PeriodIndex: 95 entries, 2010-02 to 2017-12 Freq: M Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Mkt-RF 95 non-null float64 1 SMB 95 non-null float64 2 HML 95 non-null float64 3 RMW 95 non-null float64 4 CMA 95 non-null float64 dtypes: float64(5) memory usage: 6.5 KB None다음과 같이 결과를 시각화할 수 있습니다.
window = 24 # here 24 is the number of months axis1 = plt.subplot2grid((1, 3), (0, 0)) axis2 = plt.subplot2grid((1, 3), (0, 1), colspan=2) lambdas.mean().sort_values().plot.barh(ax=axis1) lambdas.rolling(window).mean().dropna().plot( lw=1, figsize=(14, 5), sharey=True, ax=axis2 ) sns.despine() plt.tight_layout()출력:
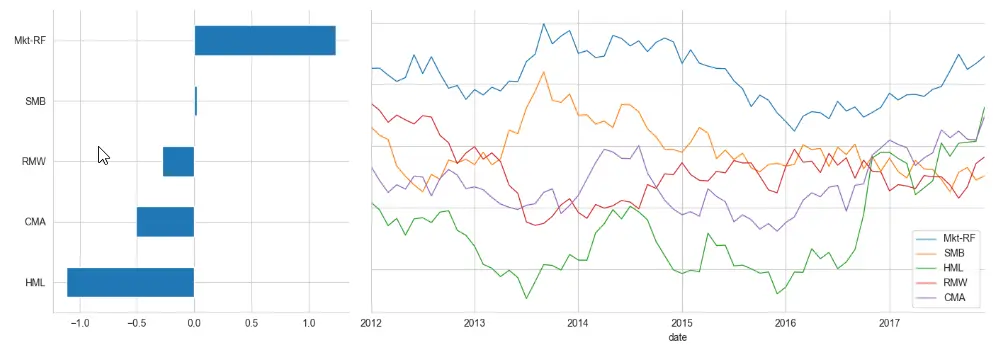
-
LinearModels모듈로 Fama-Macbeth 회귀를 구현합니다.model = LinearFactorModel( portfolios=ff_industry_portfolio_dataset, factors=ff_factor_dataset ) result = model.fit() print(result)여기에서는
LinearModels를 사용하여 다음 출력을 생성하는 2단계 Fama-Macbeth 절차를 구현합니다.print(result)대신print(result.full_summary)를 사용하여 전체 요약을 얻을 수 있습니다.출력:
LinearFactorModel Estimation Summary ================================================================================ No. Test Portfolios: 17 R-squared: 0.6879 No. Factors: 5 J-statistic: 15.619 No. Observations: 95 P-value 0.2093 Date: Mon, Oct 24 2022 Distribution: chi2(12) Time: 20:53:52 Cov. Estimator: robust Risk Premia Estimates ============================================================================== Parameter Std. Err. T-stat P-value Lower CI Upper CI ------------------------------------------------------------------------------ Mkt-RF 1.2355 0.4098 3.0152 0.0026 0.4324 2.0386 SMB 0.0214 0.8687 0.0246 0.9804 -1.6813 1.7240 HML -1.1140 0.6213 -1.7931 0.0730 -2.3317 0.1037 RMW -0.2768 0.8133 -0.3403 0.7336 -1.8708 1.3172 CMA -0.5078 0.5666 -0.8962 0.3701 -1.6183 0.6027 ============================================================================== Covariance estimator: HeteroskedasticCovariance See full_summary for complete results
Python에서 Fama-Macbeth 회귀를 구현하기 위한 대체 접근 방식
LinearModels를 사용하고 싶지 않거나 Python 버전 2를 사용하지 않으려는 경우 이 접근 방식을 사용할 수 있습니다.
-
모듈 및 라이브러리를 가져옵니다.
import pandas as pd import numpy as np import statsmodels.formula.api as sm데이터 프레임 작업을 위해
pandas를 가져오고, 배열을 사용하기 위해numpy를 가져오며, 수식 문자열과 데이터 프레임을 통해 모델을 지정하는 편리한 인터페이스인statsmodels.formula.api를 가져옵니다. -
데이터 세트를 읽고 쿼리합니다.
아래와 같이 패널에 Fama-French 산업 자산/포트폴리오가 있다고 가정합니다(예를 들어
x변수로 활용하기 위해 과거베타및수익률과 같은 몇 가지 변수도 계산했습니다).data_df = pd.read_csv("industry_data.csv", parse_dates=["caldt"]) data_df.query("caldt == '1995-07-01'")출력:
industry caldt ret beta r12to2 r36to13 18432 Aero 1995-07-01 6.26 0.9696 0.2755 0.3466 18433 Agric 1995-07-01 3.37 1.0412 0.1260 0.0581 18434 Autos 1995-07-01 2.42 1.0274 0.0293 0.2902 18435 Banks 1995-07-01 4.82 1.4985 0.1659 0.2951 -
groupby()를 사용하여 월별 단면 회귀 모델을 계산합니다.def ols_coefficient(x, formula): return sm.ols(formula, data=x).fit().params gamma_df = data_df.groupby("caldt").apply( ols_coefficient, "ret ~ 1 + beta + r12to2 + r36to13" ) gamma_df.head()여기서 Fama-Macbeth는 정확한 횡단면 회귀 모델을 월 단위로 계산하기 때문에
groupby를 사용합니다. 데이터 프레임(groupby에 의해 반환됨) 및pasty수식을 허용하는 함수를 만들 수 있습니다. 그런 다음 모델에 적합하고 매개변수 추정치를 반환합니다.출력:
Intercept beta r12to2 r36to13 caldt 1963-07-01 -1.497012 -0.765721 4.379128 -1.918083 1963-08-01 11.144169 -6.506291 5.961584 -2.598048 1963-09-01 -2.330966 -0.741550 10.508617 -4.377293 1963-10-01 0.441941 1.127567 5.478114 -2.057173 1963-11-01 3.380485 -4.792643 3.660940 -1.210426 -
평균에 대한 평균 및 표준 오차를 계산합니다.
def fm_summary(p): s = p.describe().T s["std_error"] = s["std"] / np.sqrt(s["count"]) s["tstat"] = s["mean"] / s["std_error"] return s[["mean", "std_error", "tstat"]] fm_summary(gamma_df)다음으로 평균, t-테스트(원하는 통계를 사용할 수 있음) 및 평균에 대한 표준 오차를 계산합니다. 이는 위와 같습니다.
출력:
mean std_error tstat Intercept 0.754904 0.177291 4.258000 beta -0.012176 0.202629 -0.060092 r12to2 1.794548 0.356069 5.039896 r36to13 0.237873 0.186680 1.274230 -
속도를 높이고
fama_macbeth기능을 사용하십시오.def ols_np(dataset, y_var, x_var): gamma_df, _, _, _ = np.linalg.lstsq(dataset[x_var], dataset[y_var], rcond=None) return pd.Series(gamma_df)이 단계는 효율성이 우려되는 경우 중요합니다. 그렇다면
statsmodels에서numpy.linalg.lstsq로 전환할 수 있습니다.ols추정을 수행하기 위해 위와 유사한 함수를 작성할 수 있습니다. 우리는 이러한 행렬의 순위를 확인하기 위해 아무 것도 하지 않는다는 점에 유의하십시오.이전
pandas버전을 사용하는 경우 다음이 작동합니다.pandas에서fama_macbeth를 사용하는 예를 들어 보겠습니다.print(data_df) fm = pd.fama_macbeth(y=data_df["y"], x=data_df[["x"]]) print(fm)여기에서 아래 구조를 관찰하십시오.
fama_macbeth는x-var및y-var가날짜를 첫 번째 변수로,stock/firm/entityid를 인덱스의 두 번째 변수로 갖는 다중 인덱스를 갖기를 원합니다.출력:
y x date id 2012-01-01 1 0.1 0.4 2 0.3 0.6 3 0.4 0.2 4 0.0 1.2 2012-02-01 1 0.2 0.7 2 0.4 0.5 3 0.2 0.1 4 0.1 0.0 2012-03-01 1 0.4 0.8 2 0.6 0.1 3 0.7 0.6 4 0.4 -0.1 ----------------------Summary of the Fama-Macbeth Analysis------------------------- Formula: Y ~ x + intercept # betas : 3 ----------------------Summary of the Estimated Coefficients------------------------ Variable Beta Std Err t-stat CI 2.5% CI 97.5% (x) -0.0227 0.1276 -0.18 -0.2728 0.2273 (intercept) 0.3531 0.0842 4.19 0.1881 0.5181 --------------------------------End of the Summary---------------------------------위의 코드 펜스에서 했던 것처럼
fm을 인쇄하여fm.summary를 호출하고 있음에 유의하십시오. 또한fama_macbeth는 자동으로intercept를 추가하고x-var는 데이터 프레임이어야 합니다.intercept를 원하지 않으면 다음과 같이 할 수 있습니다.fm = pd.fama_macbeth(y=data_df["y"], x=data_df[["x"]], intercept=False)
