Pandas 데이터 프레임에 메타데이터 추가
데이터에 대한 데이터라고도 하는 메타데이터는 웹 게시를 통해 웹에서 공유되는 문서의 내용을 설명하고 찾고 관리하는 구조화된 데이터입니다.
일부 웹 서버 및 소프트웨어 도구는 메타데이터를 자동으로 생성할 수 있습니다. 그러나 수동 프로세스도 가능합니다.
문서의 구성, 검색 가능성, 액세스 가능성, 인덱싱 및 검색을 향상시킬 수 있습니다.
Pandas 데이터 프레임은 R 데이터 프레임과 Python 사전의 기능을 모두 제공하는 데이터 프레임 위에 구축된 데이터 구조입니다.
Python 사전과 같지만 Excel의 테이블이나 행과 열이 있는 데이터베이스와 같은 모든 데이터 분석 및 조작 기능이 있습니다. 이 튜토리얼에서는 Pandas 데이터 프레임에 메타데이터를 추가하는 방법을 설명합니다.
Pandas 데이터 프레임에 메타데이터 추가
데이터 프레임에 메타데이터를 추가하려면 아래의 요구 사항을 충족해야 합니다.
- 데이터 프레임을 생성하거나 가져옵니다.
- 데이터 프레임의 기존 메타데이터를 읽습니다.
- 데이터 프레임에 메타데이터를 추가합니다.
데이터 프레임 생성 또는 가져오기
메타데이터를 추가하려면 데이터 프레임이 필요합니다. 이를 위해 pandas라는 Python 라이브러리를 설치해야 합니다.
PS C:\> pip install pandas
pandas를 사용하여 파일에서 데이터 프레임을 읽어 봅시다.
예제 코드(demo.py에 저장됨):
import pandas as pd
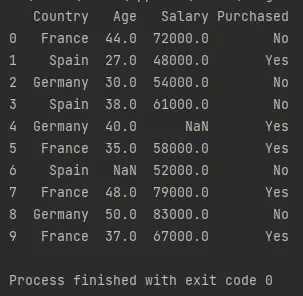
df = pd.read_csv("Data.csv")
print(df)
위의 코드는 Python 패키지 pandas를 pd로 가져옵니다. 함수 pd.read_csv()는 데이터 프레임을 가져와서 읽고 df라는 변수에 저장합니다.
pd가 무엇인지 봅시다.
출력(콘솔에 인쇄됨):
데이터 프레임의 기존 메타데이터 읽기
가져온 데이터 프레임에는 일부 기존 메타데이터도 포함되어 있습니다. 아래 주어진 코드 예제를 통해 확인할 수 있습니다.
-
Pandas
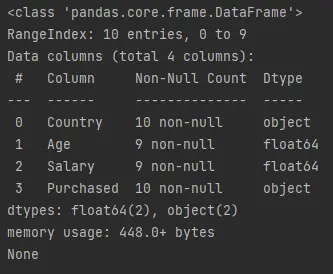
info()함수는 데이터 프레임에 대한 빠른 요약을 제공합니다.max_cols,memory_usage,show_counts및null_counts와 같은 정보를 검색합니다.df.info()를 호출하고 출력하는 아래 코드를 실행해 봅시다.예제 코드(
demo.py에 저장됨):print(df.info())출력(콘솔에 인쇄됨):
-
Pandas
columns속성은 각 데이터 프레임 열의 레이블을 포함하는Index라는 정렬된 집합의 불변 n차원 배열을 반환합니다.df.columns를 호출하고Index를 인쇄하는 아래 코드를 실행해 보겠습니다.
예제 코드(`demo.py`에 저장됨):
```python
print(df.columns)
```
출력(콘솔에 인쇄됨):

-
Pandas
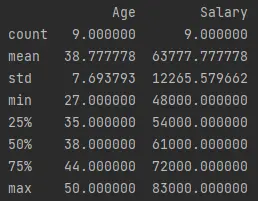
describe()함수는 데이터 프레임의 기술 통계를 생성합니다. 여기에는개수,평균및표준,최소,최대및 백분위수와 같은 표준 편차가 포함됩니다.df.describe()를 호출하고 인쇄하는 다음 코드를 실행해 보겠습니다.예제 코드(
demo.py에 저장됨):print(df.describe())출력(콘솔에 인쇄됨):
데이터 프레임에 메타데이터 추가
아래 코드를 실행하여 Pandas 데이터 프레임에 메타데이터를 추가해 보겠습니다.
예제 코드(demo.py에 저장됨):
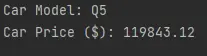
df.audi_car_model = "Q5"
df.audi_car_price_in_dollars = 119843.12
print(f"Car Model: {df.audi_car_model}")
print(f"Car Price ($): {df.audi_car_price_in_dollars}")
출력(콘솔에 인쇄됨):
참고: Python은 메타데이터를 데이터 프레임에 전파하는 강력한 방법을 제공하지 않습니다.
예를 들어 메타데이터가 첨부된 데이터 프레임에서 group_by와 같은 작업을 수행하면 메타데이터가 첨부되지 않은 이전 데이터 프레임이 반환됩니다.
그러나 나중에 처리하기 위해 메타데이터를 HDF5 파일에 저장할 수 있습니다. 아래 코드를 실행하여 HDF5 파일에 메타데이터를 저장해 보겠습니다.
예제 코드(demo.py에 저장됨):
def store_in_hdf5(filename, df, **kwargs):
hdf5_file = pd.HDFStore(filename)
hdf5_file.put("car_data", df)
hdf5_file.get_storer("car_data").attrs.metadata = kwargs
hdf5_file.close()
filename = "car data.hdf5"
metadata = {"audi_car_model": "Q5", "audi_car_price_in_dollars": 119843.12}
store_in_hdf5(filename, df, **metadata)
store_in_hdf5() 기능은 다음 기능을 수행합니다.
filename을 인수로 사용하여pd.HDFStore()함수를 사용하여hdf5_file을 만듭니다.- 적절한 이름과
df를 인수로 사용하여hdf5_file.put()을 사용하여 파일에 데이터 프레임을 삽입합니다. hdf5_file에 메타데이터를 저장합니다.hdf5_file.get_storer('car_data').attrs.metadata를 사용하고metadata를 할당합니다.hdf5_file.close()를 호출하여 파일을 닫습니다.
이제 아래 코드를 실행하여 파일에서 데이터 프레임과 메타데이터를 가져오겠습니다.
예제 코드(demo.py에 저장됨):
def import_from_file(hdf5_file):
data = hdf5_file["car_data"]
metadata = hdf5_file.get_storer("car_data").attrs.metadata
return data, metadata
filename = "car data.hdf5"
with pd.HDFStore(filename) as hdf5_file:
data, metadata = import_from_file(hdf5_file)
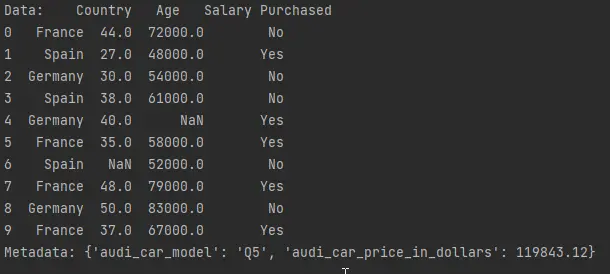
print(f"Data: {data}")
print(f"Metadata: {metadata}")
import_from_file() 함수는 hdf5_file을 인수로 사용합니다. 다음 정보를 검색합니다.
hdf5_file[]에 데이터 이름을 지정하여data.hdf5_file.get_storer('car_data').attrs.metadata함수의metadata속성을 호출하여metadata.
이제 Python 파일 demo.py를 다음과 같이 실행합니다.
PS C:>python demo.py
import_from_file() 함수에 의해 반환된 data 및 metadata를 인쇄합니다.
출력(콘솔에 인쇄됨):