Java의 Trie 데이터 구조

이 튜토리얼은 Java의 Trie 데이터 구조를 보여줍니다.
Java의 Trie 데이터 구조
Trie 단어는 문자열 집합을 저장하는 데 사용되는 정렬된 데이터 구조인 Retrieval이라는 단어에서 추출됩니다. Trie는 각 노드의 문자 수와 동일한 포인터 수를 갖는 데이터 구조로 정의할 수 있습니다.
단어의 접두사를 사용하여 Trie 데이터 구조를 사용하여 사전에서 단어를 검색할 수 있습니다. 이 시나리오에서 사전의 모든 단어가 26개의 영어 알파벳으로 만들어지면 각 Trie 노드는 26개의 포인트를 갖게 됩니다.
Trie 데이터 구조는 접두사 트리 또는 디지털 트리라고도 하며 노드의 위치에 따라 노드가 연결되는 키가 결정됩니다. Trie가 어떻게 작동하는지 다음 그림에서 이해해 봅시다.
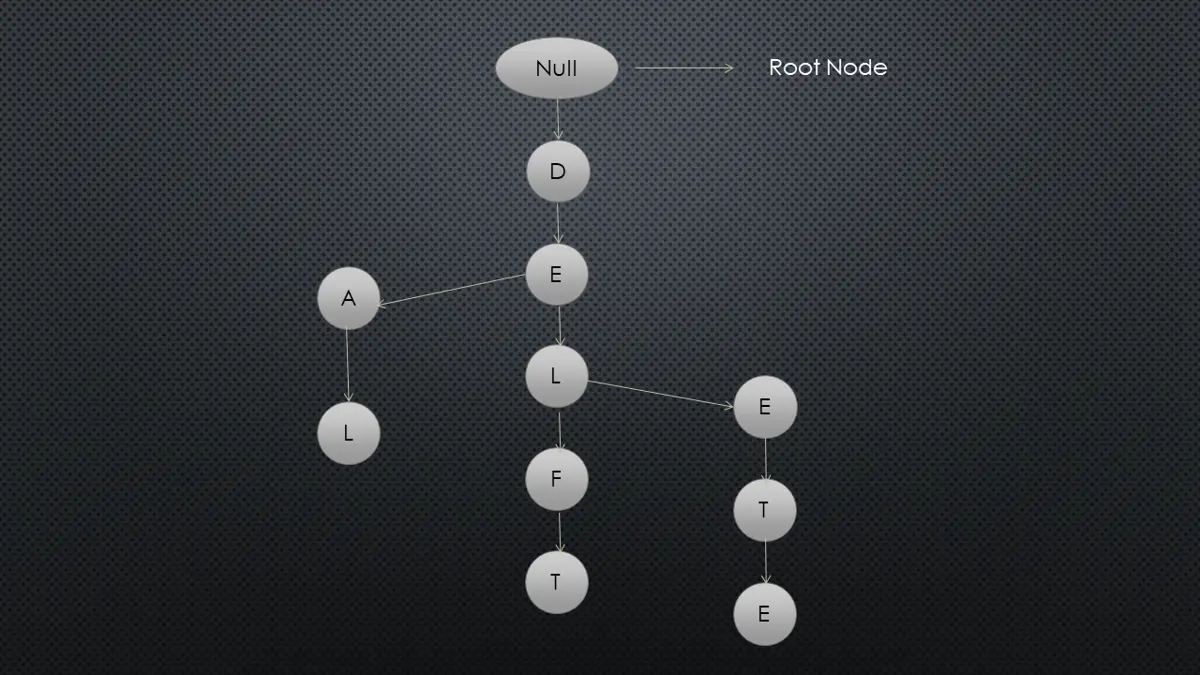
위의 그림에는 deal, delft 및 delete라는 단어에 대한 트리 구조가 포함되어 있습니다.
Trie 데이터 구조의 속성
Trie 문자열 세트의 주요 속성은 다음과 같습니다.
- 루트 노드는 항상 null 노드입니다.
- 모든 하위 노드는 알파벳순으로 정렬됩니다.
- 각 노드는 영어 알파벳 때문에 26개 이상의 자식을 가질 수 없습니다.
- 모든 노드는 알파벳에서 한 글자를 저장할 수 있습니다.
Trie 데이터 구조의 적용
Trie 데이터 구조에 대한 몇 가지 주요 응용 프로그램을 살펴보겠습니다.
- Trie는 모든 문자를 소문자로 가정할 필요가 있을 때 사용할 수 있습니다.
- 하이픈, 구두점 등 없이
a-z의 문자만 사용해야 하는 경우 - 단어의 길이가 제한된 경우. 예를 들어 2x2 보드에서 작업하는 경우 단어 길이는 4를 초과할 수 없으므로 해당 단어를 버릴 수 있습니다.
- 사전에 있는 많은 단어는 어간이 같습니다(예:
lawn및lawnmower). 이러한 굴절된 단어에는 Trie를 사용할 수 있습니다.
Trie 데이터 구조의 기본 연산
Trie에는 세 가지 기본 작업이 있습니다.
삽입 작업
첫 번째 작업은 Trie에 노드를 삽입하는 것입니다. 그러기 위해서는 다음 사항을 이해해야 합니다.
- 입력 단어의 모든 문자는 Trie 노드에 개별적으로 삽입됩니다.
- 문자 길이는 Trie의 길이를 결정합니다.
- 키 문자 배열은 자식 인덱스 역할을 합니다.
- 현재 노드에 현재 문자에 대한 참조가 있는 경우 해당 노드를 참조한 현재 노드를 설정합니다. 그렇지 않으면 새 노드를 만들어야 합니다.
검색 작업
Trie의 두 번째 기본 작업은 노드를 검색하는 것입니다. 이 작업도 삽입과 유사합니다.
동일한 접근 방식을 사용하여 노드를 검색하기만 하면 됩니다.
작업 삭제
세 번째 작업은 노드를 삭제하는 것입니다. 이것은 또한 쉬운 작업입니다.
삭제를 시작하기 전에 두 가지 사항을 고려해야 합니다.
- 검색 중에 노드 키를 찾지 못하면 삭제 작업이 중지되고 종료됩니다.
- Trie를 검색하는 동안 노드 키가 발견되면 삭제 작업이 키를 삭제합니다.
Trie 데이터 구조의 Java 구현
소문자 a-z 영어 문자만 지원하는 Trie 데이터 구조를 구현해 보겠습니다. 예를 참조하십시오:
package delftstack;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
class Trie_Node {
// 26 characters for a – z
private static final int CHARACTER_SIZE = 26;
private boolean Is_Leaf;
private List<Trie_Node> Trie_Children = null;
// Constructor
Trie_Node() {
Is_Leaf = false;
Trie_Children = new ArrayList<>(Collections.nCopies(CHARACTER_SIZE, null));
}
// function for insertion
public void Insertion(String Node_Key) {
System.out.println("Inserting the key \"" + Node_Key + "\"");
// root node
Trie_Node root_node = this;
// repeat for every character of the key
for (char character : Node_Key.toCharArray()) {
// create a new Trie node if the path does not exist
if (root_node.Trie_Children.get(character - 'a') == null) {
root_node.Trie_Children.set(character - 'a', new Trie_Node());
}
// going to the next node
root_node = root_node.Trie_Children.get(character - 'a');
}
// current node as a leaf
root_node.Is_Leaf = true;
}
// Method for search
public boolean Searching(String Node_Key) {
System.out.print("Searching the key \"" + Node_Key + "\" : ");
Trie_Node Current_Node = this;
// repeat for the character of the key
for (char character : Node_Key.toCharArray()) {
// going to the next node
Current_Node = Current_Node.Trie_Children.get(character - 'a');
// reach out to the end of a path in the Trie if the string is invalid
if (Current_Node == null) {
return false;
}
}
return Current_Node.Is_Leaf;
}
}
public class Example {
public static void main(String[] args) {
// construct a new Trie node
Trie_Node New_Trie = new Trie_Node();
New_Trie.Insertion("delft");
New_Trie.Insertion("delf");
New_Trie.Insertion("del");
System.out.println(New_Trie.Searching("del")); // true
System.out.println(New_Trie.Searching("delf")); // true
System.out.println(New_Trie.Searching("delft")); // true
System.out.println(New_Trie.Searching("delftstack")); // false
New_Trie.Insertion("delftstack");
System.out.println(New_Trie.Searching("del")); // true
System.out.println(New_Trie.Searching("delf")); // true
System.out.println(New_Trie.Searching("delft")); // true
System.out.println(New_Trie.Searching("delftstack")); // true
}
}
위의 코드는 Trie 데이터 구조의 삽입 및 검색 작업을 구현합니다. 출력을 참조하십시오.
Inserting the key "delft"
Inserting the key "delf"
Inserting the key "del"
Searching the key "del" : true
Searching the key "delf" : true
Searching the key "delft" : true
Searching the key "delftstack" : false
Inserting the key "delftstack"
Searching the key "del" : true
Searching the key "delf" : true
Searching the key "delft" : true
Searching the key "delftstack" : true
이제 Trie 데이터 구조의 공간 복잡도는 O(N × M × C)입니다.
N- 문자열의 수M- 스트링의 최대 길이.C- 알파벳의 크기
따라서 위의 공간 복잡성을 가진 Java에서 스토리지 문제가 발생할 수 있습니다.
저장 문제를 해결하기 위해 Trie를 구현하기 위해 Java의 HashMap을 사용할 수도 있습니다. HashMap을 사용하여 Trie를 구현해 봅시다.
package delftstack;
import java.util.HashMap;
import java.util.Map;
class Trie_Node {
private boolean Is_Leaf;
private Map<Character, Trie_Node> Trie_Children;
// Constructor
Trie_Node() {
Is_Leaf = false;
Trie_Children = new HashMap<>();
}
// Insertion
public void Insertion(String Node_Key) {
System.out.println("Inserting the key \"" + Node_Key + "\"");
// root node
Trie_Node root_node = this;
for (char character : Node_Key.toCharArray()) {
// if the path doesn't exist, create a new node.
root_node.Trie_Children.putIfAbsent(character, new Trie_Node());
// going to the next node
root_node = root_node.Trie_Children.get(character);
}
root_node.Is_Leaf = true;
}
// Searching
public boolean Searching(String Node_key) {
System.out.print("Searching the key \"" + Node_key + "\" : ");
Trie_Node Current_Node = this;
// repeat
for (char character : Node_key.toCharArray()) {
// going to the next node
Current_Node = Current_Node.Trie_Children.get(character);
if (Current_Node == null) {
return false;
}
}
return Current_Node.Is_Leaf;
}
}
public class Example {
public static void main(String[] args) {
// construct a new Trie node
Trie_Node New_Trie = new Trie_Node();
New_Trie.Insertion("delft");
New_Trie.Insertion("delf");
New_Trie.Insertion("del");
System.out.println(New_Trie.Searching("del")); // true
System.out.println(New_Trie.Searching("delf")); // true
System.out.println(New_Trie.Searching("delft")); // true
System.out.println(New_Trie.Searching("delftstack")); // false
New_Trie.Insertion("delftstack");
System.out.println(New_Trie.Searching("del")); // true
System.out.println(New_Trie.Searching("delf")); // true
System.out.println(New_Trie.Searching("delft")); // true
System.out.println(New_Trie.Searching("delftstack")); // true
}
}
코드는 동일한 작업을 수행하지만 보다 메모리 효율적인 방식으로 수행됩니다. Java에서 Trie에 대한 출력을 참조하십시오.
Inserting the key "delft"
Inserting the key "delf"
Inserting the key "del"
Searching the key "del" : true
Searching the key "delf" : true
Searching the key "delft" : true
Searching the key "delftstack" : false
Inserting the key "delftstack"
Searching the key "del" : true
Searching the key "delf" : true
Searching the key "delft" : true
Searching the key "delftstack" : true

Sheeraz is a Doctorate fellow in Computer Science at Northwestern Polytechnical University, Xian, China. He has 7 years of Software Development experience in AI, Web, Database, and Desktop technologies. He writes tutorials in Java, PHP, Python, GoLang, R, etc., to help beginners learn the field of Computer Science.
LinkedIn Facebook