Trie estructura de datos en Java
- Trie estructura de datos en Java
- Operaciones básicas de la estructura de datos Trie
- Implementación Java de la estructura de datos Trie

Este tutorial demuestra la estructura de datos Trie en Java.
Trie estructura de datos en Java
Trie word se extrae de la palabra Retrieval, que es una estructura de datos ordenados utilizada para almacenar el conjunto de cadenas. Trie se puede definir como la estructura de datos con el número de punteros igual al número de caracteres en cada nodo.
Con la ayuda del prefijo de la palabra, la estructura de datos de Trie se puede utilizar para buscar una palabra en un diccionario. En este escenario, si todas las palabras del diccionario están formadas por los 26 alfabetos ingleses, cada nodo Trie tendrá 26 puntos.
La estructura de datos Trie también se conoce como árbol de prefijos o árbol digital, donde la posición del nodo determinará la clave con la que se conectará el nodo. Tratemos de entender a partir de la siguiente figura cómo funciona un Trie:
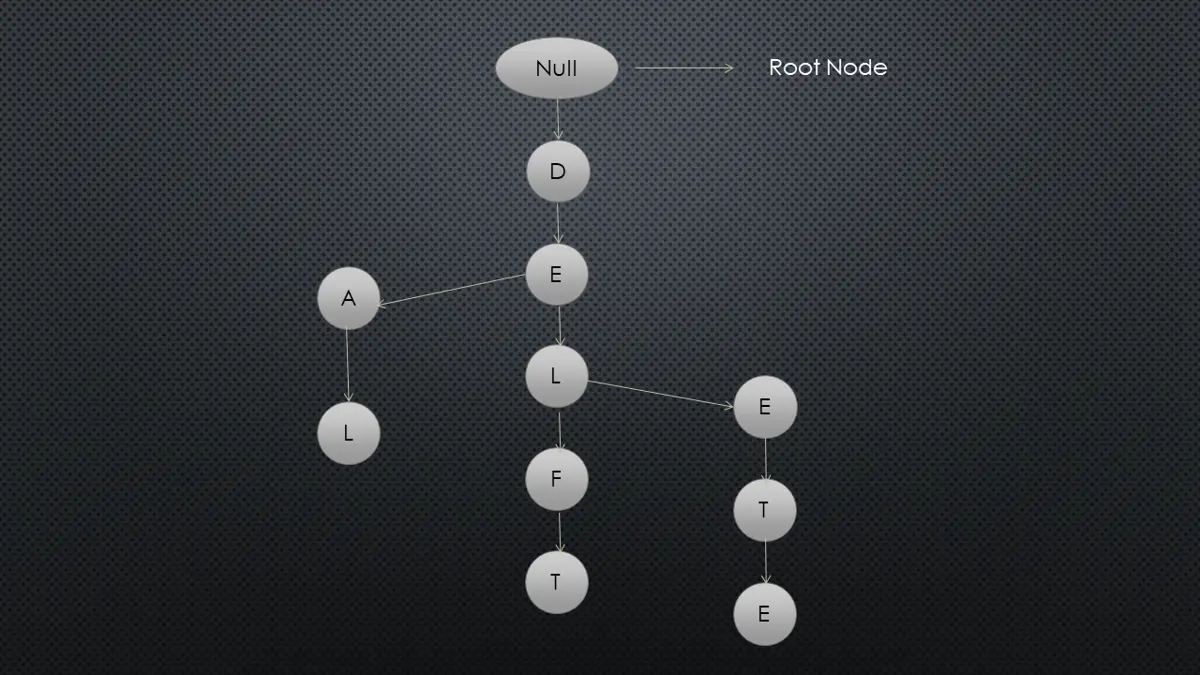
La imagen de arriba contiene la estructura de árbol para las palabras acuerdo, delft y eliminar.
Propiedades de la estructura de datos Trie
Estas son las principales propiedades del conjunto de cadenas Trie:
- El nodo Raíz es siempre el nulo.
- Cada nodo secundario se ordenará alfabéticamente.
- Cada nodo no puede tener más de 26 hijos debido al alfabeto inglés.
- Cada nodo puede almacenar una letra del alfabeto.
Aplicación de la estructura de datos Trie
Veamos algunas aplicaciones principales para la estructura de datos Trie:
- El Trie se puede utilizar cuando es necesario suponer que todas las letras están en minúsculas.
- Cuando tengamos que utilizar únicamente la letra de la
a-z, sin guión, sin puntuación, etc. - Cuando las palabras tengan una longitud limitada. Por ejemplo, si estamos trabajando en un tablero de 2x2, la longitud de la palabra no puede ser superior a 4, por lo que esas palabras se pueden descartar.
- Muchas palabras del diccionario comparten la misma raíz, por ejemplo,
céspedycortacésped. El Trie se puede utilizar para estas palabras flexionadas.
Operaciones básicas de la estructura de datos Trie
El Trie tiene tres operaciones básicas:
Insertar operación
La primera operación es insertar un nodo en el Trie. Para hacer eso, necesitamos entender los siguientes puntos:
- Cada letra de la palabra de entrada se insertará individualmente en un nodo Trie.
- La longitud del carácter determinará la longitud del Trie.
- La matriz de caracteres clave actuará como el índice de los niños.
- Si el nodo actual tiene una referencia a la letra actual, configure el nodo actual que hace referencia al nodo. De lo contrario, se debe crear un nuevo nodo.
Operación de búsqueda
La segunda operación básica de Trie es buscar un nodo. Esta operación también es similar a la inserción.
Solo tenemos que buscar un nodo usando el mismo enfoque.
Eliminar operación
La tercera operación es eliminar un nodo. Esta es también una operación fácil.
Tenemos que tener en cuenta dos puntos antes de iniciar la eliminación:
- Si no se encuentra la clave de nodo durante la búsqueda, la operación de eliminación se detendrá y finalizará.
- Si se encuentra la clave de nodo mientras se busca el Trie, la operación de eliminación eliminará la clave.
Implementación Java de la estructura de datos Trie
Intentemos implementar la estructura de datos Trie, que solo admite caracteres ingleses en minúsculas a-z. Ver ejemplo:
package delftstack;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
class Trie_Node {
// 26 characters for a – z
private static final int CHARACTER_SIZE = 26;
private boolean Is_Leaf;
private List<Trie_Node> Trie_Children = null;
// Constructor
Trie_Node() {
Is_Leaf = false;
Trie_Children = new ArrayList<>(Collections.nCopies(CHARACTER_SIZE, null));
}
// function for insertion
public void Insertion(String Node_Key) {
System.out.println("Inserting the key \"" + Node_Key + "\"");
// root node
Trie_Node root_node = this;
// repeat for every character of the key
for (char character : Node_Key.toCharArray()) {
// create a new Trie node if the path does not exist
if (root_node.Trie_Children.get(character - 'a') == null) {
root_node.Trie_Children.set(character - 'a', new Trie_Node());
}
// going to the next node
root_node = root_node.Trie_Children.get(character - 'a');
}
// current node as a leaf
root_node.Is_Leaf = true;
}
// Method for search
public boolean Searching(String Node_Key) {
System.out.print("Searching the key \"" + Node_Key + "\" : ");
Trie_Node Current_Node = this;
// repeat for the character of the key
for (char character : Node_Key.toCharArray()) {
// going to the next node
Current_Node = Current_Node.Trie_Children.get(character - 'a');
// reach out to the end of a path in the Trie if the string is invalid
if (Current_Node == null) {
return false;
}
}
return Current_Node.Is_Leaf;
}
}
public class Example {
public static void main(String[] args) {
// construct a new Trie node
Trie_Node New_Trie = new Trie_Node();
New_Trie.Insertion("delft");
New_Trie.Insertion("delf");
New_Trie.Insertion("del");
System.out.println(New_Trie.Searching("del")); // true
System.out.println(New_Trie.Searching("delf")); // true
System.out.println(New_Trie.Searching("delft")); // true
System.out.println(New_Trie.Searching("delftstack")); // false
New_Trie.Insertion("delftstack");
System.out.println(New_Trie.Searching("del")); // true
System.out.println(New_Trie.Searching("delf")); // true
System.out.println(New_Trie.Searching("delft")); // true
System.out.println(New_Trie.Searching("delftstack")); // true
}
}
El código anterior implementa la operación de inserción y búsqueda de la estructura de datos Trie. Ver la salida:
Inserting the key "delft"
Inserting the key "delf"
Inserting the key "del"
Searching the key "del" : true
Searching the key "delf" : true
Searching the key "delft" : true
Searching the key "delftstack" : false
Inserting the key "delftstack"
Searching the key "del" : true
Searching the key "delf" : true
Searching the key "delft" : true
Searching the key "delftstack" : true
Ahora, la complejidad espacial para la estructura de datos Trie es O(N × M × C), donde:
N- el número de cadenasM- la longitud máxima de las cuerdas.C- el tamaño del alfabeto
Entonces, el problema de almacenamiento podría ocurrir en Java con la complejidad de espacio anterior.
También podemos usar el HashMap de Java para implementar Trie para resolver el problema de almacenamiento. Intentemos implementar el Trie usando HashMap:
package delftstack;
import java.util.HashMap;
import java.util.Map;
class Trie_Node {
private boolean Is_Leaf;
private Map<Character, Trie_Node> Trie_Children;
// Constructor
Trie_Node() {
Is_Leaf = false;
Trie_Children = new HashMap<>();
}
// Insertion
public void Insertion(String Node_Key) {
System.out.println("Inserting the key \"" + Node_Key + "\"");
// root node
Trie_Node root_node = this;
for (char character : Node_Key.toCharArray()) {
// if the path doesn't exist, create a new node.
root_node.Trie_Children.putIfAbsent(character, new Trie_Node());
// going to the next node
root_node = root_node.Trie_Children.get(character);
}
root_node.Is_Leaf = true;
}
// Searching
public boolean Searching(String Node_key) {
System.out.print("Searching the key \"" + Node_key + "\" : ");
Trie_Node Current_Node = this;
// repeat
for (char character : Node_key.toCharArray()) {
// going to the next node
Current_Node = Current_Node.Trie_Children.get(character);
if (Current_Node == null) {
return false;
}
}
return Current_Node.Is_Leaf;
}
}
public class Example {
public static void main(String[] args) {
// construct a new Trie node
Trie_Node New_Trie = new Trie_Node();
New_Trie.Insertion("delft");
New_Trie.Insertion("delf");
New_Trie.Insertion("del");
System.out.println(New_Trie.Searching("del")); // true
System.out.println(New_Trie.Searching("delf")); // true
System.out.println(New_Trie.Searching("delft")); // true
System.out.println(New_Trie.Searching("delftstack")); // false
New_Trie.Insertion("delftstack");
System.out.println(New_Trie.Searching("del")); // true
System.out.println(New_Trie.Searching("delf")); // true
System.out.println(New_Trie.Searching("delft")); // true
System.out.println(New_Trie.Searching("delftstack")); // true
}
}
El código hace el mismo trabajo pero de una manera más eficiente en memoria. Vea la salida para Trie en Java:
Inserting the key "delft"
Inserting the key "delf"
Inserting the key "del"
Searching the key "del" : true
Searching the key "delf" : true
Searching the key "delft" : true
Searching the key "delftstack" : false
Inserting the key "delftstack"
Searching the key "del" : true
Searching the key "delf" : true
Searching the key "delft" : true
Searching the key "delftstack" : true

Sheeraz is a Doctorate fellow in Computer Science at Northwestern Polytechnical University, Xian, China. He has 7 years of Software Development experience in AI, Web, Database, and Desktop technologies. He writes tutorials in Java, PHP, Python, GoLang, R, etc., to help beginners learn the field of Computer Science.
LinkedIn Facebook