Pandas データ フレームにメタデータを追加する
データに関するデータとも呼ばれるメタデータは、Web パブリッシングを通じて Web 上で共有されるドキュメントのコンテンツを記述、検索、および管理する構造化データです。
一部の Web サーバーおよびソフトウェア ツールは、メタデータを自動的に生成できます。 ただし、手動プロセスも実行可能です。
ドキュメントの編成、見つけやすさ、アクセシビリティ、インデックス作成、および検索を向上させることができます。
Pandas データ フレームは、データ フレームの上に構築されたデータ構造であり、R データ フレームと Python 辞書の両方の機能を提供します。
これは Python の辞書に似ていますが、Excel のテーブルや行と列を持つデータベースなど、すべてのデータ分析および操作機能を備えています。 このチュートリアルでは、Pandas データ フレームへのメタデータの追加について説明します。
Pandas データ フレームにメタデータを追加する
メタデータをデータ フレームに追加するには、以下の要件を満たす必要があります。
- データ フレームを作成またはインポートします。
- データ フレームの既存のメタデータを読み取ります。
- メタデータをデータ フレームに追加します。
データ フレームの作成またはインポート
メタデータを追加するには、データ フレームが必要です。 この目的のために、pandas という Python ライブラリをインストールする必要があります。
PS C:\> pip install pandas
pandas を使用して、ファイルからデータ フレームを読み込んでみましょう。
コード例 (demo.py に保存):
import pandas as pd
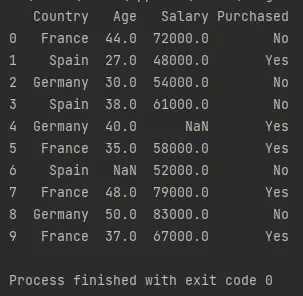
df = pd.read_csv("Data.csv")
print(df)
上記のコードは、Python パッケージ pandas を pd としてインポートします。 関数 pd.read_csv() は、データ フレームをインポートして読み取り、df という名前の変数に保存します。
pd とは何かを見てみましょう。
出力 (コンソールに出力):
データ フレームの既存のメタデータを読み取る
インポートされたデータ フレームには、いくつかの既存のメタデータも含まれています。 以下のコード例で確認できます。
-
Pandas の
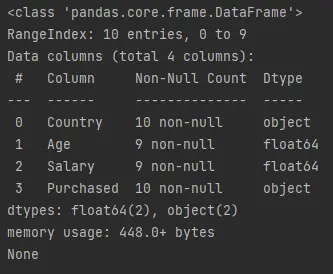
info()関数は、データ フレームの簡単な要約を提供します。max_cols、memory_usage、show_counts、null_countsなどの情報を取得します。df.info()を呼び出して出力する以下のコードを実行してみましょう。コード例 (
demo.pyに保存):print(df.info())出力 (コンソールに出力):
-
Pandas
columns属性は、各データ フレーム列のラベルを含むIndexと呼ばれる順序付けられたセットの不変の n 次元配列を返します。df.columnsを呼び出してIndexを出力する以下のコードを実行してみましょう。
コード例 (`demo.py` に保存):
```python
print(df.columns)
```
出力 (コンソールに出力):

-
Pandas
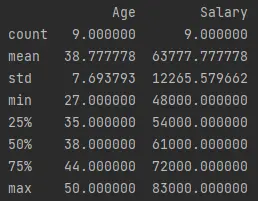
describe()関数は、データ フレームの記述統計を生成します。 これには、count、mean、およびstd、min、max、およびパーセンタイルとしての標準偏差が含まれます。df.describe()を呼び出して出力する次のコードを実行しましょう。コード例 (
demo.pyに保存):print(df.describe())出力 (コンソールに出力):
データ フレームにメタデータを追加する
以下のコードを実行して、Pandas データ フレームにメタデータを追加しましょう。
コード例 (demo.py に保存):
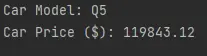
df.audi_car_model = "Q5"
df.audi_car_price_in_dollars = 119843.12
print(f"Car Model: {df.audi_car_model}")
print(f"Car Price ($): {df.audi_car_price_in_dollars}")
出力 (コンソールに出力):
注: Python は、メタデータをデータ フレームに伝達するための強力な方法を提供していません。
たとえば、メタデータが添付されたデータ フレームで group_by などの操作を行うと、メタデータが添付されていない前のデータ フレームが返されます。
ただし、後で処理するために、メタデータを HDF5 ファイルに保存できます。 以下のコードを実行して、メタデータを HDF5 ファイルに保存してみましょう。
コード例 (demo.py に保存):
def store_in_hdf5(filename, df, **kwargs):
hdf5_file = pd.HDFStore(filename)
hdf5_file.put("car_data", df)
hdf5_file.get_storer("car_data").attrs.metadata = kwargs
hdf5_file.close()
filename = "car data.hdf5"
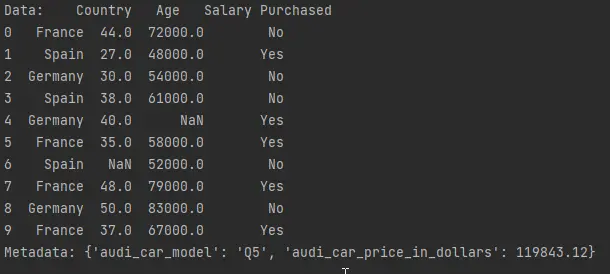
metadata = {"audi_car_model": "Q5", "audi_car_price_in_dollars": 119843.12}
store_in_hdf5(filename, df, **metadata)
store_in_hdf5() 関数は次の機能を実行します。
filenameを引数としてpd.HDFStore()関数を使用してhdf5_fileを作成します。- 引数として適切な名前と
dfを取って、hdf5_file.put()を使用してデータ フレームをファイルに挿入します。 - メタデータを
hdf5_fileに保存します。hdf5_file.get_storer('car_data').attrs.metadataを使用し、それにmetadataを割り当てます。 hdf5_file.close()を呼び出してファイルを閉じます。
それでは、以下のコードを実行して、ファイルからデータ フレームとメタデータをインポートしましょう。
コード例 (demo.py に保存):
def import_from_file(hdf5_file):
data = hdf5_file["car_data"]
metadata = hdf5_file.get_storer("car_data").attrs.metadata
return data, metadata
filename = "car data.hdf5"
with pd.HDFStore(filename) as hdf5_file:
data, metadata = import_from_file(hdf5_file)
print(f"Data: {data}")
print(f"Metadata: {metadata}")
import_from_file() 関数は hdf5_file を引数として取ります。 次の情報を取得します。
hdf5_file[]でデータの名前を指定してdata。- 関数
hdf5_file.get_storer('car_data').attrs.metadataのmetadata属性を呼び出すことによるmetadata。
次に、Python ファイル demo.py を次のように実行します。
PS C:>python demo.py
import_from_file() 関数によって返された data と metadata を出力します。
出力 (コンソールに出力):