PowerShell を使用して XML ファイルを解析する方法
-
PowerShell を使用して XML ファイルを解析するために
Select-Xmlを使用する -
PowerShell を使用して XML ファイルを解析するために
System.Xml.XmlDocumentクラスを使用する -
PowerShell を使用して XML ファイルを解析するために
System.Xml.XmlTextReaderクラスを使用する - 結論

拡張可能なマークアップ言語、または XML 形式は、今日でも広く使用されています。構成ファイル、RSS フィード、Office ファイルは、XML 形式を使用するいくつかの例です。
PowerShell で XML を解析することは一般的なタスクであり、データ抽出、構成管理、および自動化などのタスクにしばしば必要とされます。PowerShell は XML を解析するためのいくつかの方法を提供していますが、各方法にはそれぞれの強みと使用例があります。
この記事では、PowerShell で XML を解析するための 3つの方法を探ります:Select-Xml コマンドレット、System.Xml.XmlDocument クラス、System.Xml.XmlTextReader クラスの使用です。各方法の構文、機能、および実用的なアプリケーションを強調しながら、詳細な例と説明を提供します。
PowerShell を使用して XML ファイルを解析するために Select-Xml を使用する
PowerShell XML 要素を解析する
まず、Select-XML を使用して PowerShell で XML を解析する最も人気があり簡単な方法の 1つをカバーします。Select-XmlPowerShell コマンドを使うことで、XML ファイルまたは文字列と XPath フィルターを指定して特定の情報を抽出することができます。
私たちは、PowerShell を使用して解析したい XML ファイルが多くの PC にあります。たとえば、各マシンには名前、IP アドレス、およびレポートに使用できる Include 要素があります。
例 XML:
<Computers>
<Computer>
<Name>WINPC-01</Name>
<Ip>127.0.0.1</Ip>
<Include>true</Include>
</Computer>
<Computer>
<Name>WINPC-02</Name>
<Ip>192.168.1.105</Ip>
<Include>false</Include>
</Computer>
<Computer>
<Name>WINPC-03</Name>
<Ip>192.168.1.104</Ip>
<Include>true</Include>
</Computer>
</Computers>
私たちは PowerShell を使用してこの XML ファイルを解析し、コンピュータ名を取得したいと考えています。そのために、Select-XML コマンドを使用できます。
たとえば、上記のファイルでは、コンピュータ名は Name 要素の内部テキスト(InnerXML)に表示されます。
最初に、コンピュータ名を見つけるための適切な XPath を提供します。この XPath 技術を使用すると、Computer 要素に含まれる Name ノードだけが返されます。
例コード:
Select-Xml -Path sample.xml -XPath '/Computers/Computer/Name' | ForEach-Object { $_.Node.InnerXML }
Select-Xml を使用して、C:\path\sample.xml にある XML ファイルを'/Computers/Computer/Name'の XPath 式に一致するノードを検索します。この XPath 式は、PowerShell に <Computers> ルートノードの下にある各 <Computer> 要素内のすべての <Name> 要素を選択するよう指示します。
次に、ForEach-Object コマンドレットを利用して、Select-Xml コマンドレットが返した結果を反復処理します。このループ内で、各一致したノードの InnerXML プロパティにアクセスします。
このプロパティには、XML 要素の内部テキストコンテンツが含まれており、必要なデータを抽出することができます。
出力:

PowerShell XML 属性を解析する
次に、コンピュータ名を見つけるための新しいアプローチを検討しましょう。コンピュータの記述が XML 要素として表されるのではなく、XML 属性として直接表現されます。
以下は、属性で表されたコンピュータの記述を含む例 XML ファイルです。各記述を要素ではなく属性として表示することができます。
例 XML:
<Computers>
<Computer name="WINPC-01" ip="127.0.0.1" include="true" />
<Computer name="WINPC-02" ip="192.168.1.104" include="false" />
<Computer name="WINPC-03" ip="192.168.1.105" include="true" />
</Computers>
各記述が属性であるため、XPath を調整して Computer 要素のみを見つけることにします。次に、ForEach-Object コマンドレットを使用して、name 属性の値を見つけます。
例コード:
Select-Xml -Path sample.xml -XPath '/Computers/Computer' | ForEach-Object { $_.Node.name }
Select-Xml を使用して、C:\path\computers-attr.xml にある XML ファイルを'/Computers/Computer'の XPath 式に一致するノードを検索します。この XPath 式は、<Computers> ルートノードの下にあるすべての <Computer> 要素を選択します。
次に、ForEach-Object コマンドレットを使用して結果を反復処理します。ループ内では、各一致したノードの name プロパティにアクセスします。このプロパティは、各 <Computer> 要素の name 属性の値を表します。
出力:

要素を読み取っている場合でも属性を読み取っている場合でも、Select-Xml の構文は煩雑です。XPath パラメータを使用することを強制し、その後、結果をループにパイプし、最後に Node プロパティの下でデータを探す必要があります。
PowerShell を使用して XML ファイルを解析するために System.Xml.XmlDocument クラスを使用する
PowerShell における XML 解析のための System.Xml.XmlDocument クラスは、XML データを処理するための多目的で効果的なソリューションを提供し、さまざまな自動化タスク、データ処理、および構成管理シナリオにとって貴重なツールとなります。
この方法では、XmlDocument クラスのインスタンスを作成し、XML コンテンツをドキュメントオブジェクトにロードし、その後ドキュメントのノードをナビゲートして必要なデータにアクセスします。
例コード:
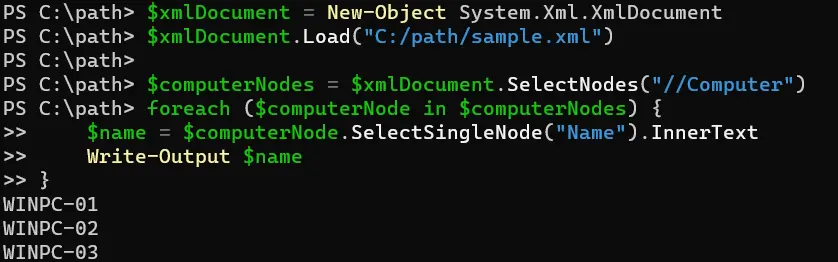
$xmlDocument = New-Object System.Xml.XmlDocument
$xmlDocument.Load("sample.xml")
$computerNodes = $xmlDocument.SelectNodes("//Computer")
foreach ($computerNode in $computerNodes) {
$name = $computerNode.SelectSingleNode("Name").InnerText
Write-Output $name
}
このコードスニペットでは、New-Object を使用して System.Xml.XmlDocument クラスの新しいインスタンスを作成します。その後、Load メソッドを使用して、ファイル C:\path\computers.xml から XML コンテンツを $xmlDocument オブジェクトにロードします。
SelectNodes メソッドを使用して、XML ドキュメント内のすべての <Computer> 要素を取得します。
次に、foreach ループを使用して各 <Computer> ノードを反復処理します。ループ内では、SelectSingleNode を使って各 <Computer> ノード内の <Name> 要素を見つけ、その内部テキストを InnerText プロパティを使って抽出します。
最後に、Write-Output を使用してコンピュータ名を出力します。
出力:
PowerShell を使用して XML ファイルを解析するために System.Xml.XmlTextReader クラスを使用する
PowerShell で XML を解析するために System.Xml.XmlTextReader クラスを使用することは、XML データを処理するための簡単でメモリー効率の良い方法を提供します。このクラスは、XML データを効率的に解析するための前方のみ、読み取り専用のストリームを提供し、完全なドキュメントをメモリに読み込むことなく処理することができます。
XmlTextReader を利用することで、PowerShell スクリプトは XML ドキュメントから特定の要素や属性を効率的に抽出し、データ抽出、構成管理、自動化などのタスクを実行できるようになります。
例コード:
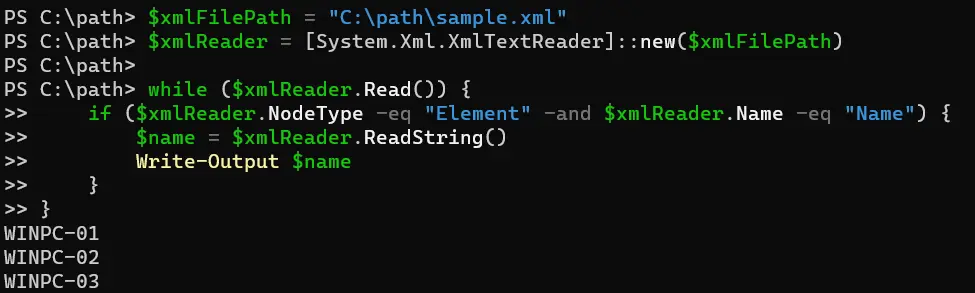
$xmlFilePath = "sample.xml"
$xmlReader = [System.Xml.XmlTextReader]::new($xmlFilePath)
while ($xmlReader.Read()) {
if ($xmlReader.NodeType -eq "Element" -and $xmlReader.Name -eq "Name") {
$name = $xmlReader.ReadString()
Write-Output $name
}
}
このコードスニペットでは、$xmlFilePath 変数を使用して XML ファイルへのパスを指定します。その後、System.Xml.XmlTextReader クラスの新しいインスタンスを作成し、$xmlFilePath で指定されたファイルの XML コンテンツで初期化します。
XmlTextReader クラスの Read メソッドを使用して、XML コンテンツを反復処理するために while ループを使用します。ループ内では、現在のノードタイプが要素であり、その名前が Name であるかどうかを確認します。
両方の条件が満たされている場合は、ReadString メソッドを使用して <Name> 要素の内部テキストを抽出し、それを Write-Output で出力します。
出力:
結論
PowerShell で XML を解析することは、多くの自動化およびデータ処理タスクにおいて多目的で重要なスキルです。Select-Xml、System.Xml.XmlDocument、および System.Xml.XmlTextReader などのさまざまな方法を理解することで、PowerShell ユーザーは XML ドキュメントから効率的にデータを抽出して操作することができます。
要素を解析するか属性を解析するかにかかわらず、各方法にはそれぞれの利点があり、PowerShell スクリプトが XML データを効果的に扱うことを可能にします。これらの解析技術を活用することで、PowerShell ユーザーはワークフローを合理化し、自動化の目標をより効率的に達成できます。

Marion specializes in anything Microsoft-related and always tries to work and apply code in an IT infrastructure.
LinkedIn