MySQL 再帰クエリ
このガイドでは、MySQL の recursive クエリについて学習します。 このガイドでは、SQL で recursive クエリを作成する方法とその仕組みについて説明し、理解を深めます。
MySQL 再帰 クエリ
SQL の recursive クエリはサブクエリです。 名前が示すように、再帰的に機能します。 これには、基本ケース、ユーザー定義名、および終了条件付きの再帰ケースがあります。
with [Recursive] CTE(user_defined name) AS
(
SELECT query (Non Recursive query or the Base query)
UNION
SELECT query (recursive query using the name [with a termination condition])
)
SELECT * from CTE_name;
上記は recursive SQL クエリの疑似コードです。 より深く掘り下げてみましょう。
with 節
with [Recursive] CTE(user_defined name) AS
SQL の with 句は、SQL の Recursive キーワードと一緒に最初に使用されます。 次に、AS キーワードが使用され、その後にユーザー定義の名前である CTE が続きます。
このキーワードの構文は、クエリの基本ケースを構成します。
CTE は common table expression と呼ばれ、後で後続の SELECT ステートメントで使用するためにユーザーが定義した一時的な名前付き結果セットです。
ベースクエリ
SELECT query (Non Recursive query or the Base query)
これは、ベース クエリと呼ばれる 2つのクエリの最初のクエリです。 これは非再帰クエリであり、再帰が発生するベース入力がここで提供されます。
連合条項
UNION
Union 演算子は、最初と 2 番目のクエリをマージするために途中で使用されます。
再帰クエリ
SELECT query (recursive query using the name [with a termination condition])
これは、with 句を使用して以前に作成した CTE テーブルを提供する必要がある recursive クエリであり、また、true になると再帰を終了する終了条件も提供する必要があります。
上記の疑似コードに示すように、Base および Recursive クエリは括弧 () 内に記述されます。
SELECT * from CTE_name
このクエリは、この再帰手法を使用して作成されたテーブルを表示します。
MySQL で Recursive クエリを実装する
適切に実装して、このクエリの動作を理解しましょう。
with recursive number_printer AS
(
SELECT 1 AS digit
UNION
SELECT digit+1 FROM number_printer WHERE digit<5
)
SELECT * FROM number_printer
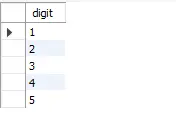
上の表は、プログラムの実行結果です。 これが実行された方法です。
クエリは、with 句と recursive キーワードを使用して開始し、CTE として print_number を使用しました。 コードを実行するとすぐに、プログラムはそれが再帰クエリであることを理解するため、基本ケースを探します。
ベース クエリでは、ベース ケースを 1 から開始しました。ここで使用されるエイリアスは digit です。 実行の最初の繰り返しでは、出力は基本クエリから返された結果になります。
初期レコードは、ベース クエリの出力になります。
基本クエリから返された結果は、再帰クエリの入力になります。 2 回目の反復では、再帰クエリは前のクエリからの出力データを使用し、終了条件をチェックします。
終了条件が満たされた場合、反復は停止します。 それ以外の場合は、3 番目の反復に入ります。 3 番目の反復では、2 番目の反復で返された出力を入力として使用します。
これは、再帰の発生に基づく唯一のロジックです。
3 番目の反復が実行され、この反復の結果の出力が 4 番目の反復の入力として使用されます。 次に、4 回目の繰り返しで、ベース クエリの出力とその入力が追加されます。
終了条件が満たされるまで、再帰的に発生し続けます。
ここでは、number_printer というテーブルが非常に重要です。 このクエリを再帰的にするには、テーブルを使用する必要があります。 クエリの終了は、WHERE 句を使用して終了条件を記述します。
ここで、再帰クエリに関する別の例を見てみましょう。
例 2: 階層
何らかの階層を持つ組織があるとします。 トップにマネージャーがいて、そのマネージャーの直属のマネージャーが 2 人いて、この 2 人のマネージャーのそれぞれに直属のマネージャーがいます。
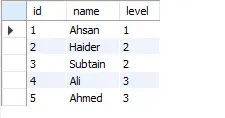
これで、id、name、ManagerID などの列を持つ network というテーブルが作成されました。 これらはそれぞれ、従業員の ID、名前、およびマネージャー ID を定義します。
次の表に示します。
上の表では、従業員の名前とマネージャー ID を取得しましたが、前述の階層に基づいて、これらのマネージャーにランクを適切に割り当てたいと考えています。 そのため、次のコードを使用します。
WITH RECURSIVE hierarchy AS
( SELECT id, name, 1 AS level FROM network WHERE id = 1
UNION
SELECT n.id, n.name, h.level+1 FROM hierarchy h
JOIN network n on h.id = n.ManagerID
)
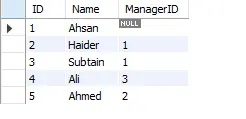
SELECT * FROM hierarchy
上記の再帰クエリ コードは、私たちが望んでいた問題を解決します。 このコードが何をするのかを理解してみましょう。
With 句は構文に従って Recursive キーワードと一緒に使用され、ここでの CTE は hierarchy と名付けられています。
基本クエリでは、network テーブルから id と name を選択し、id が 1 に等しい値をフェッチします。 次に、値 AS level を整数 1 に設定します。
level は、階層内のマネージャーの位置を示すためにここで使用されます。
基本クエリはこれで完了です。 ここで、コードは UNION 句を使用して基本クエリを再帰クエリとマージします。
再帰クエリは、network テーブルから id と name を選択します。 ここでの n は network テーブルのエイリアスであり、このドット (.) がここで行うことは、その前に入力として指定した特定のテーブルからフェッチされる値を制限することです。
h は hierarchy テーブルのエイリアスであり、level+1 節は hierarchy テーブルから取得した整数値に 1 を追加することを保証します。
再帰クエリのこの部分は、network テーブルから name と id を取得し、整数値は hierarchy から取得され、1 が追加され、出力が level に保存されます。 . このクエリは、マネージャーのレベルを更新および定義します。
クエリの次の部分では、JOIN 句が使用されます。これは、デフォルト値で 内部結合 として機能します。 ここで、network テーブルの ManagerID は hierarchy テーブルの id と照合され、上記のクエリで内部結合されます。
ロジックは、マネージャー ID が ID と一致すると、マネージャーのレベルに 1 を追加することによって、そのエンティティーへのレベルが割り当てられるというものです。 このようにして、監督のランクが割り当てられます。

Haider specializes in technical writing. He has a solid background in computer science that allows him to create engaging, original, and compelling technical tutorials. In his free time, he enjoys adding new skills to his repertoire and watching Netflix.
LinkedIn