MongoDB でレコードを数える
- MongoDB での操作
- MongoDB での集計操作
-
MongoDB の
$count -
MongoDB の
db.collection.count() - カウントによるMongoDBグループ
- MongoDB Group by Count ソート
- 複数フィールドのカウントによるMongoDBグループ
- 日付と数によるMongoDBグループ
-
MongoDB の
.toArray()メソッド -
MongoDB の
.itcount()

この記事では、MongoDB の演算子、aggregate 演算子、および合計レコード数をカウントするさまざまな方法について説明します。
MongoDB での操作
CRUD 操作は、ユーザーがデータベース内のオブジェクトを参照、検索、および変更できるようにするユーザー インターフェイスの概念です。
MongoDB ドキュメントは、サーバーに接続し、適切なドキュメントをクエリしてから、そのデータをデータベースに送信して処理する前に変換することによって変更されます。 CRUD は、HTTP アクション動詞を使用して標準化するデータ駆動型のプロセスです。
作成- MongoDB データベースに新しいドキュメントを挿入するために使用されます。Read- データベース内のドキュメントを照会するために使用されます。更新- データベース内の既存のドキュメントを変更するために使用されます。削除- データベース内のドキュメントを削除します。
MongoDB での集計操作
これは、グループ化されたデータに対して多くの操作を実行して 1つの結果を生成するステージで構成されるデータ処理操作です。 aggregate 操作を実行するための 3つのオプションを次に示します。
-
集約のためのパイプライン - ドキュメントはマルチステージ パイプラインを介して提供され、1つの出力に統合されます。 MongoDB の集計プロセスは複数の段階に分かれています。
以下に例を示します。
db.collection_name.aggregate([ //First stage { $match: { status: "" } }, //Second stage { $group: { _id: "$cust_id", total: { $sum: "$amount" } } }, //Third Stage { $sort : {sort_field: -1 }} ])
- 単一目的の集計方法 - 単一目的の集計方法は簡単ですが、集計パイプラインの機能が不足しています。
- Map-Reduce - MongoDB 5.0 以降、Map-Reduce 操作は廃止されました。 代わりに、集約パイプラインを使用してください。
MongoDB の $count
受信したレコード数のカウントとともに、ドキュメントを次のステップに送信します。
行動:
次の $group + $project シーケンスは $count ステージに相当します。
db.collection.aggregate( [
{ $group: { _id: null, myCount: { $sum: 1 } } },
{ $project: { _id: 2 } }
] )
myCount が示す場合、出力フィールドにはカウントが含まれます。 出力フィールドに別の名前を付けることができます。
例:
scores という名前のコレクションには、指定されたドキュメントがあります。
{ "_id" : 1, "subject" : "English", "score" : 88 }
{ "_id" : 2, "subject" : "English", "score" : 92 }
{ "_id" : 3, "subject" : "English", "score" : 97 }
{ "_id" : 4, "subject" : "English", "score" : 71 }
{ "_id" : 5, "subject" : "English", "score" : 79 }
{ "_id" : 6, "subject" : "English", "score" : 83 }
次の集計操作には 2つの段階があります。
$matchステージは80以下のscore値を持つドキュメントを除外し、80より大きいscoreを持つドキュメントを次のステージに進めます。$countステップは、集計パイプラインに残っているドキュメントの数を計算し、その結果をpassing_scoresという名前の変数に格納します。
db.scores.aggregate(
[
{
$match: {
score: {
$gt: 80
}
}
},
{
$count: "passing_scores"
}
]
)
この操作により、次の結果が返されます。
{ "passing_scores" : 4 }
1000 レコードを取得する場合、これは平均 2 ミリ秒かかり、最速の方法です。
MongoDB の db.collection.count()
find() クエリに一致するコレクションまたはビュー内のレコードの数を返します。 db.collection.count() 関数は、find() プロシージャではなく、クエリに一致する結果の数をカウントして提供します。
行動:
トランザクションでは、count またはシェル ツール count() および db.collection.count() を使用できません。
シャード クラスタ
孤立したドキュメントが存在するか、チャンクの移行が進行中の場合、分割されたクラスターでクエリ述語なしで db.collection.count() を使用すると、誤ったカウントが発生する可能性があります。
このような状況を防ぐには、シャード クラスターで db.collection.aggregate() 関数を使用します。
ドキュメントをカウントするには、$count ステップを使用します。 たとえば、次の手順では、コレクション内のドキュメントをカウントします。
db.collection.aggregate( [
{ $count: "myCount" }
])
$count ステージは、次の $group + $project シーケンスと同じです。
db.collection.aggregate( [
{ $group: { _id: null, count: { $sum: 1 } } }
{ $project: { _id: 0 } }
] )
インデックスの使用
次のインデックスを持つコレクションを考えてみましょう。
{ a: 1, b: 1 }
カウントを実行するとき、MongoDB はインデックスを使用してカウントを返すことができるのは、クエリが次の場合のみです。
- インデックスを使用できます。
- インデックスのキーに関する条件のみを含み、かつ
- インデックス キーの単一の連続した範囲への述語アクセス
たとえば、インデックスのみを指定すると、次のプロシージャはカウントを返すことができます。
db.collection.find( { a: 5, b: 5 } ).count()
db.collection.find( { a: { $gt: 5 } } ).count()
db.collection.find( { a: 5, b: { $gt: 10 } } ).count()
クエリがインデックスを使用する可能性があるが、述語がインデックス キーの単一の連続した範囲に到達しないとします。 クエリには、インデックス外のフィールドに対する条件もあります。
その場合、MongoDB はインデックスを使用してカウントを提供するだけでなく、ドキュメントを読み取る必要があります。
db.collection.find( { a: 6, b: { $in: [ 1, 2, 3 ] } } ).count()
db.collection.find( { a: { $gt: 6 }, b: 5 } ).count()
db.collection.find( { a: 5, b: 5, c: 8 } ).count()
このような状況では、MongoDB は最初の読み取り中にドキュメントをメモリにページングし、同じカウント操作への後続の呼び出しの速度を向上させます。
予期しないシャットダウンが発生した場合の精度
count() によって提供されるカウント統計は、Wired Tiger ストレージ エンジンを利用する mongod のクリーンでないシャットダウンの後、誤っている可能性があります。
最後のチェックポイントからクリーンでないシャットダウンまでの間に、実行された挿入、更新、または削除操作の数によってドリフトの量が決まります。
チェックポイントは平均で 60 秒ごとに発生します。 一方、デフォルト以外の -syncdelay オプションを持つ mongod インスタンスは、より多くのまたはより少ないチェックポイントを持つ場合があります。
クリーンでないシャットダウンの後に統計を復元するには、mongod の各コレクションに対して validate を実行します。
クリーンでないシャットダウンの後:
validateはcollStats出力のカウント統計を最新の値で更新します。collStats出力で挿入または削除されたドキュメントの数などのその他の統計は推定値です。
クライアントの切断
MongoDB 4.2 から、操作が完了する前に db.collection.count() を発行したクライアントが切断された場合、MongoDB は killOp を使用して終了するように db.collection.count() をマークします。
コレクション内のすべてのドキュメントを数える
orders コレクション内のすべてのレコードの数をカウントするには、次の操作を使用します。
db.orders.count()
この操作は以下と同等です。
db.orders.find().count()
クエリに一致するすべてのドキュメントをカウントする
orders コレクションで、new Date('01/01/2012') より大きいフィールド ord_dt を持つドキュメントの数を数えます。
db.orders.count( { ord_dt: { $gt: new Date('01/01/2012') } } )
クエリは次と同等です。
db.orders.find( { ord_dt: { $gt: new Date('01/01/2012') } } ).count()
カウントによるMongoDBグループ
MongoDB の各ドキュメントの _id 列には、値によって一意のグループが割り当てられています。 次に、集計手法によってデータが処理され、計算結果が生成されます。
以下は一例です。 データベースのセットアップは、ここで表示できます。
この設定は、この記事で紹介するすべてのコード サンプルで使用されます。
db={
"data": [
{
"_id": ObjectId("611a99100a3322fc1bd8c38b"),
"fname": "Tom",
"city": "United States of America",
"courses": [
"c#",
"asp",
"node"
]
},
{
"_id": ObjectId("611a99340a3322fc1bd8c38c"),
"fname": "Harry",
"city": "Canada",
"courses": [
"python",
"asp",
"node"
]
},
{
"_id": ObjectId("611a99510a3322fc1bd8c38d"),
"fname": "Mikky",
"city": "New Zealand",
"courses": [
"python",
"asp",
"c++"
]
},
{
"_id": ObjectId("611b3e88a60b5002406571c3"),
"fname": "Ron",
"city": "United Kingdom",
"courses": [
"python",
"django",
"node"
]
}
]
}
使用される上記のデータベースのクエリは次のとおりです。
db.data.aggregate([
{
$group: {
_id: "ObjectId",
count: {
$count: {}
}
}
}
])
上記の実行の リンク は、このコード セグメントの動作を確認するために提供されています。
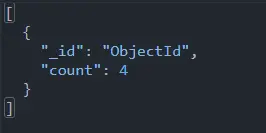
MongoDB Group by Count ソート
このセクションでは、$group + $sort と同じ $sortByCount が使用されます。 人々のグループを昇順および降順でソートおよびカウントできます。
クエリの例を以下に示します。 この例では、いくつかのドキュメントがデータ コレクションに追加されており、find() メソッドを使用して含まれるエントリの数を特定しています。
以下は find() のクエリになります。
db.data.find()
この リンク からこのクエリの実行にアクセスできます。
次のステップは、courses の配列を undo し、$sortByCount 関数を使用して、各コースに追加されたレコードの数をカウントすることです。
db.data.aggregate([
{
$unwind: "$courses"
},
{
$sortByCount: "$courses"
}
])
リンク は、上記のデータベース構成でこのクエリが機能することを確認するためにここに提供されています。 これは、配列をカウントして並べ替えるという、MongoDB グループへの最も簡単なアプローチです。
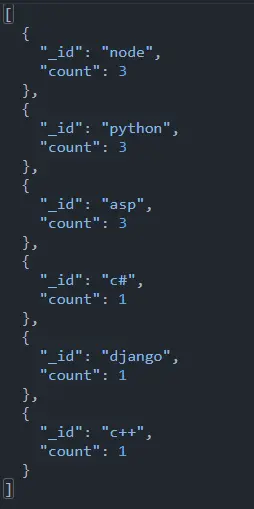
複数フィールドのカウントによるMongoDBグループ
MongoDB の aggregate() 関数は、複数のフィールドをカウントする場合があります。 その結果、フィールドは $count を使用してカウントされます。
以下は、タイムスタンプが 1つのエントリのみに使用される例です。 この例では、一部のドキュメントを student コレクションに保存できます。また、find() メソッドを使用して、所有しているドキュメントの数を確認できます。
db.student.aggregate([ {$group: {_id: {name:"$name",
timestamp:"$timestamp" }}},
{$count:"timestamp"}
])
このクエリの実行は、この リンク でアクセスできます。
日付と数によるMongoDBグループ
特定の日付ドキュメントをカウントする必要がある場合は、カウント集計を使用して特定の日付ドキュメントをカウントできます。
これがイラストです。 この例では、2021 年の各日の全体的な販売額と販売数を計算する方法を学習します。
sales コレクションには、product id、item name、price、quantity、および date フィールドを含めることができます。 ドキュメントは find() メソッドを使用して取得できます。
db=
{
"_id" : 1,
"item" : "abc",
"price" : NumberDecimal("10"),
"quantity" : 2,
"date" : ISODate("2021-03-01T08:00:00Z")
}
{
"_id" : 2,
"item" : "jkl",
"price" : NumberDecimal("20"),
"quantity" : 1,
"date" : ISODate("2021-03-01T09:00:00Z")
}
{
"_id" : 3,
"item" : "xyz",
"price" : NumberDecimal("5"),
"quantity" : 10,
"date" : ISODate("2021-03-15T09:00:00Z")
}
{
"_id" : 4,
"item" : "xyz",
"price" : NumberDecimal("5"),
"quantity" : 20,
"date" : ISODate("2021-04-04T11:21:39.736Z")
}
{
"_id" : 5,
"item" : "abc",
"price" : NumberDecimal("10"),
"quantity" : 10,
"date" : ISODate("2021-04-04T21:23:13.331Z")
}
上記の構成のクエリは次のようになります。
db.date.aggregate([
{
$match : { "date": { $gte: new ISODate("2021-01-01"), $lt: new ISODate("2015-01-01") } }
},
{
$group : {
_id : { $dateToString: { format: "%Y-%m-%d", date: "$date" } },
totalSaleAmount: { $sum: { $multiply: [ "$price", "$quantity" ] } },
count: { $sum: 1 }
}
},
{
$sort : { totalSaleAmount: -1 }
}
])
ここで、count および field コマンドを使用して、単一のフィールドおよび複数のフィールド グループのクエリを以下に示します。
-
単一フィールドのグループ化とカウント
db.Request.aggregate([{'$group': {_id: '$source', count: {$sum: 1}}}])
-
複数のフィールドのグループ化とカウント
db.Request.aggregate([ {'$group': {_id: {source: '$source', status: '$status'}, count: {$sum: 1}}} ]) -
複数のフィールドは、フィールドを使用して並べ替えでグループ化し、カウントします
db.Request.aggregate([ {'$group': {_id: {source: '$source', status: '$status'}, count: {$sum: 1}}}, {$sort: {'_id.source': 1}} ]) -
複数のフィールドのグループ化とcountを使用した並べ替えによるカウント
db.Request.aggregate([ {'$group': {_id: {source: '$source', status: '$status'}, count: {$sum: 1}}}, {$sort: {'count': -1}} ])
MongoDB の .toArray() メソッド
toArray() 関数は、カーソル内のすべてのドキュメントを含む配列を返します。 このプロシージャはカーソルを何度もループし、すべてのドキュメントを RAM にロードしてポインターを使い果たします。
toArray() 関数を使用して、find() メソッドによって返されたカーソルを変換する次の例を考えてみましょう。
var allProductsArray = db.products.find().toArray();
if (allProductsArray.length > 0) {
printjson(allProductsArray[0]);
}
変数 allProductsArray は、toArray() によって返されるドキュメントの配列を保持します。 1000 レコードを取得するには、平均で 18 ミリ秒かかります。
MongoDB の .itcount()
カーソル内に残っているドキュメントの数をカウントします。
itcount() は cursor.count() に似ていますが、新しいイテレータでクエリを実行する代わりに、既存のイテレータでクエリを実行し、その内容を使い果たします。
itcount() メソッドのプロトタイプ形式は次のとおりです。
db.collection.find(<query>).itcount()
1000 レコードを取得するには、平均で 14 ミリ秒かかります。
この記事では操作について詳しく説明し、aggregate 操作についても説明しました。 まず、さまざまな種類の集計関数について、コード セグメントを使用して簡単に説明しました。
次に、グループ化して count について議論し、ソート、検索、および複数のフィールドについて議論しました。 次に、MongoDB でレコードをカウントするさまざまな方法について説明します。