Fonction SciPy stats.skew
-
La fonction
scipy.stats.skew -
Calcul de l’asymétrie à l’aide de
numpy.linspace() - Calcul de l’asymétrie à l’aide de données aléatoires
L’asymétrie dans les statistiques est définie comme une mesure de la symétrie de la distribution de certaines données. Le point qui se trouve au sommet de toute la distribution est appelé mode. L’asymétrie est calculée par la formule suivante.
Skewness = 3(Mean - Median) / Standard Deviation
Conditions d’asymétrie :
- Si
skewness = 0, alors les données sont distribuées normalement. - Si
skewness > 0, alors les données sont davantage pondérées du côté gauche de la distribution. - Si
skewness < 0, alors les données sont plus pondérées du côté droit de la distribution.
La fonction scipy.stats.skew
La fonction scipy.stats.skew de la librairie SciPy permet de déterminer la valeur de skewness d’une donnée donnée. Cette fonction est définie comme scipy.stats.skew(a, axis, bias, nan_policy).
Voici les paramètres de la fonction scipy.stats.skew.
a (ndarray) |
Il définit le tableau d’entrée, c’est-à-dire les données d’entrée. |
axis (int) |
Il définit l’axe le long duquel la fonction calcule la valeur skewness. La valeur par défaut est 0, c’est-à-dire que la fonction calcule sur l’ensemble du tableau. |
bais (bool) |
Si la valeur de ce paramètre est False, alors tous les calculs sont corrigés pour le biais statistique. |
nan_policy |
Il décide de la manière de traiter les valeurs NaN dans les données d’entrée. Il y a trois paramètres de décision dans le paramètre, propagate, raise, omit. propagate renvoie simplement la valeur NaN, raise renvoie une erreur et omit ignore simplement les valeurs NaN et la fonction continue le calcul. Ces paramètres de décision sont définis entre guillemets simples ''. De plus, la valeur par défaut est propagate. |
Tous les paramètres sauf le paramètre a (ndarray) sont facultatifs. Cela signifie qu’il n’est pas nécessaire de les définir à chaque fois lors de l’utilisation de la fonction scipy.stats.skew.
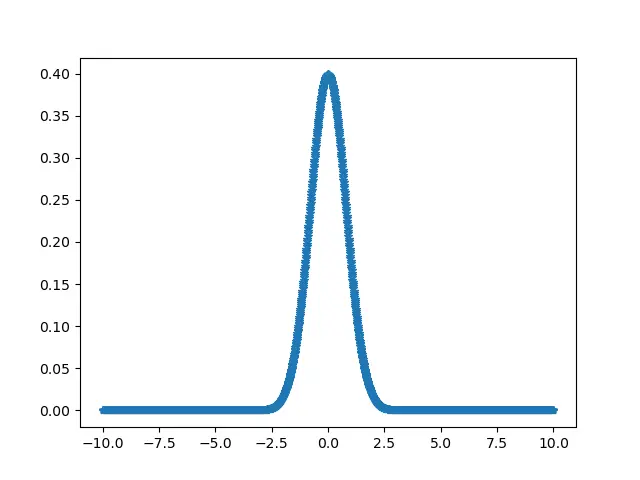
Calcul de l’asymétrie à l’aide de numpy.linspace()
La fonction linespace() de la bibliothèque NumPy aide à créer des séquences numériques aléatoires régulièrement espacées.
from scipy.stats import skew
import numpy as np
import pylab as p
x = np.linspace(-10, 10, 1000)
y = 1 / (np.sqrt(4 * np.pi)) * np.exp(-0.2 * (x) ** 2)
p.plot(x, y, ".")
p.show()
print("Skewness for the input data : ", skew(y))
Production :
Skewness for the input data : 1.458658437437705
Calcul de l’asymétrie à l’aide de données aléatoires
La fonction np.random.normal de la bibliothèque NumPy est utilisée dans cette méthode. Cette fonction aide à créer un tableau d’une forme et d’une taille spécifiées qui se compose de valeurs aléatoires qui font en fait partie de la distribution gaussienne.
from scipy.stats import skew
import numpy as np
s = np.random.normal(0, 5, 10000)
print("S : ", s)
print("Skewness for input data : ", skew(s))
S : [ 2.52232305 5.66398738 2.72036031 ... 0.53774684 -0.31164153
1.99714612]
Skewness for input data : 0.0027004583356120505

Lakshay Kapoor is a final year B.Tech Computer Science student at Amity University Noida. He is familiar with programming languages and their real-world applications (Python/R/C++). Deeply interested in the area of Data Sciences and Machine Learning.
LinkedIn