Pandas DataFrame DataFrame.to_excel() Fonction
-
Syntaxe de
pandas.DataFrame.to_excel() -
Exemples de codes: Pandas
DataFrame.to_excel() -
Exemples de codes: Pandas
DataFrame.to_excel()avecExcelWriter -
Exemples de codes: Pandas
DataFrame.to_excelà ajouter à un fichier Excel existant -
Exemples de codes: Pandas
DataFrame.to_excelpour écrire plusieurs feuilles -
Exemples de codes: Pandas
DataFrame.to_excelavec le paramètreheader -
Exemples de codes: Pandas
DataFrame.to_excelavecindex = False -
Exemples de codes: Pandas
DataFrame.to_excelavec le paramètreindex_label -
Exemples de codes: Pandas
DataFrame.to_excelavec le paramètrefloat_format -
Exemples de codes: Pandas
DataFrame.to_excelavec le paramètrefreeze_panes
Python Pandas DataFrame.to_excel(values) la fonction transfère les données du cadre de données dans un fichier Excel, en une ou plusieurs feuilles.
Syntaxe de pandas.DataFrame.to_excel()
DataFrame.isin(
excel_writer,
sheet_name="Sheet1",
na_rep="",
float_format=None,
columns=None,
header=True,
index=True,
index_label=None,
startrow=0,
startcol=0,
engine=None,
merge_cells=True,
encoding=None,
inf_rep="inf",
verbose=True,
freeze_panes=None,
)
Paramètres
excel_writer |
Chemin du fichier Excel ou des pandas.ExcelWriter existants |
sheet_name |
Nom de la feuille vers laquelle la trame de données est transférée |
na_rep |
Représentation des valeurs nulles. |
float_format |
Format des nombres flottants |
header |
Spécifiez l’en-tête du fichier Excel généré. |
index |
Si True, écrivez le cadre de données index dans Excel. |
index_label |
Libellé de colonne pour la colonne d’index. |
startrow |
La ligne de cellule supérieure gauche pour écrire les données dans Excel. La valeur par défaut est 0 |
startcol |
La colonne de cellule supérieure gauche pour écrire les données dans Excel. La valeur par défaut est 0 |
engine |
Paramètre facultatif pour spécifier le moteur à utiliser. openyxl ou xlswriter |
merge_cells |
Fusionner MultiIndex dans les cellules fusionnées |
encoding |
Encodage du fichier Excel de sortie. Nécessaire uniquement si un écrivain xlwt est utilisé, d’autres écrivains prennent en charge Unicode en mode natif. |
inf_rep |
Représentation de l’infini. La valeur par défaut est inf |
verbose |
Si True, les journaux d’erreurs contiennent plus d’informations |
freeze_panes |
Spécifiez le bas et le plus à droite du volet gelé. Il est basé sur un, mais pas sur zéro. |
Revenir
None
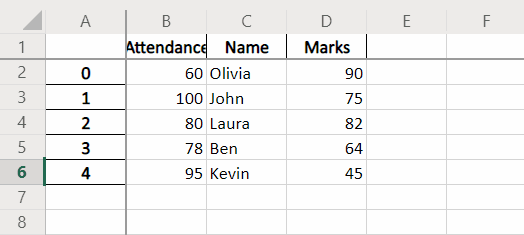
Exemples de codes: Pandas DataFrame.to_excel()
import pandas as pd
dataframe= pd.DataFrame({'Attendance': [60, 100, 80, 78, 95],
'Name': ['Olivia', 'John', 'Laura', 'Ben', 'Kevin'],
'Marks': [90, 75, 82, 64, 45]})
dataframe.to_excel('test.xlsx')
L’appelant DataFrame est
Attendance Name Marks
0 60 Olivia 90
1 100 John 75
2 80 Laura 82
3 78 Ben 64
4 95 Kevin 45
test.xlsx est créé.

Exemples de codes: Pandas DataFrame.to_excel() avec ExcelWriter
L’exemple ci-dessus utilise le chemin du fichier comme excel_writer, et nous pourrions également utiliser pandas.Excelwriter pour spécifier le fichier excel que les trames de données sauvegardent.
import pandas as pd
dataframe = pd.DataFrame(
{
"Attendance": [60, 100, 80, 78, 95],
"Name": ["Olivia", "John", "Laura", "Ben", "Kevin"],
"Marks": [90, 75, 82, 64, 45],
}
)
with pd.ExcelWriter("test.xlsx") as writer:
dataframe.to_excel(writer)
Exemples de codes: Pandas DataFrame.to_excel à ajouter à un fichier Excel existant
import pandas as pd
import openpyxl
dataframe = pd.DataFrame(
{
"Attendance": [60, 100, 80, 78, 95],
"Name": ["Olivia", "John", "Laura", "Ben", "Kevin"],
"Marks": [90, 75, 82, 64, 45],
}
)
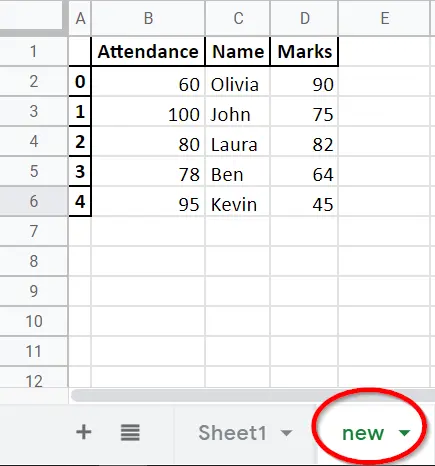
with pd.ExcelWriter("test.xlsx", mode="a", engine="openpyxl") as writer:
dataframe.to_excel(writer, sheet_name="new")
Nous devons spécifier le moteur comme openpyxl mais pas par défaut xlsxwriter; sinon, nous obtiendrons l’erreur que xlswriter ne prend pas en charge le mode append.
ValueError: Append mode is not supported with xlsxwriter!
openpyxl doit être installé et importé car il ne fait pas partie de pandas.
pip install openpyxl
Exemples de codes: Pandas DataFrame.to_excel pour écrire plusieurs feuilles
import pandas as pd
dataframe = pd.DataFrame(
{
"Attendance": [60, 100, 80, 78, 95],
"Name": ["Olivia", "John", "Laura", "Ben", "Kevin"],
"Marks": [90, 75, 82, 64, 45],
}
)
with pd.ExcelWriter("test.xlsx") as writer:
dataframe.to_excel(writer, sheet_name="Sheet1")
dataframe.to_excel(writer, sheet_name="Sheet2")
Il vide l’objet de trame de données à la fois dans Sheet1 et Sheet2.
Vous pouvez également écrire différentes données sur plusieurs feuilles si vous spécifiez le paramètre columns.
import pandas as pd
dataframe = pd.DataFrame(
{
"Attendance": [60, 100, 80, 78, 95],
"Name": ["Olivia", "John", "Laura", "Ben", "Kevin"],
"Marks": [90, 75, 82, 64, 45],
}
)
with pd.ExcelWriter("test.xlsx") as writer:
dataframe.to_excel(writer, columns=["Name", "Attendance"], sheet_name="Sheet1")
dataframe.to_excel(writer, columns=["Name", "Marks"], sheet_name="Sheet2")
Exemples de codes: Pandas DataFrame.to_excel avec le paramètre header
import pandas as pd
dataframe = pd.DataFrame(
{
"Attendance": [60, 100, 80, 78, 95],
"Name": ["Olivia", "John", "Laura", "Ben", "Kevin"],
"Marks": [90, 75, 82, 64, 45],
}
)
with pd.ExcelWriter("test.xlsx") as writer:
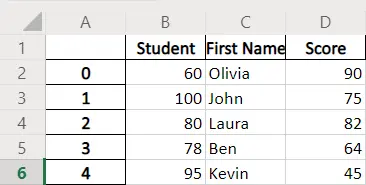
dataframe.to_excel(writer, header=["Student", "First Name", "Score"])
L’en-tête par défaut dans le fichier Excel créé est le même que les noms de colonne de la trame de données. Le paramètre header spécifie le nouvel en-tête pour remplacer celui par défaut.
Exemples de codes: Pandas DataFrame.to_excel avec index = False
import pandas as pd
dataframe = pd.DataFrame(
{
"Attendance": [60, 100, 80, 78, 95],
"Name": ["Olivia", "John", "Laura", "Ben", "Kevin"],
"Marks": [90, 75, 82, 64, 45],
}
)
with pd.ExcelWriter("test.xlsx") as writer:
dataframe.to_excel(writer, index=False)
index = False spécifie que DataFrame.to_excel() génère un fichier Excel sans ligne d’en-tête.
Exemples de codes: Pandas DataFrame.to_excel avec le paramètre index_label
import pandas as pd
dataframe = pd.DataFrame(
{
"Attendance": [60, 100, 80, 78, 95],
"Name": ["Olivia", "John", "Laura", "Ben", "Kevin"],
"Marks": [90, 75, 82, 64, 45],
}
)
with pd.ExcelWriter("test.xlsx") as writer:
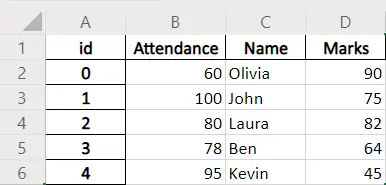
dataframe.to_excel(writer, index_label="id")
index_label = 'id' définit le nom de la colonne de la colonne d’index sur id.
Exemples de codes: Pandas DataFrame.to_excel avec le paramètre float_format
import pandas as pd
dataframe = pd.DataFrame(
{
"Attendance": [60, 100, 80, 78, 95],
"Name": ["Olivia", "John", "Laura", "Ben", "Kevin"],
"Marks": [90, 75, 82, 64, 45],
}
)
with pd.ExcelWriter("test.xlsx") as writer:
dataframe.to_excel(writer, float_format="%.1f")
float_format ="%.1f" spécifie le nombre flottant pour avoir deux chiffres flottants.
Exemples de codes: Pandas DataFrame.to_excel avec le paramètre freeze_panes
import pandas as pd
dataframe = pd.DataFrame(
{
"Attendance": [60, 100, 80, 78, 95],
"Name": ["Olivia", "John", "Laura", "Ben", "Kevin"],
"Marks": [90, 75, 82, 64, 45],
}
)
with pd.ExcelWriter("test.xlsx") as writer:
dataframe.to_excel(writer, freeze_panes=(1, 1))
freeze_panes = (1,1) spécifie que le fichier Excel a la ligne supérieure gelée et la première colonne gelée.

Founder of DelftStack.com. Jinku has worked in the robotics and automotive industries for over 8 years. He sharpened his coding skills when he needed to do the automatic testing, data collection from remote servers and report creation from the endurance test. He is from an electrical/electronics engineering background but has expanded his interest to embedded electronics, embedded programming and front-/back-end programming.
LinkedIn Facebook