Bosque aleatorio en R
Se crea una gran cantidad de árboles de decisión en el enfoque Random Forest. Este tutorial demuestra cómo aplicar el enfoque de bosque aleatorio en R.
Bosque aleatorio en R
Se crea una gran cantidad de árboles de decisión en el enfoque Random Forest. Muchas observaciones se introducen en los árboles de decisión, y el resultado más común de ellos se utiliza como resultado final.
Luego, se envía una nueva observación a todos los árboles de decisión para obtener un voto mayoritario para cada modelo de clasificación. Se realiza una estimación del error OOB (out-of-bag) para las cajas que no se utilizaron durante la construcción del árbol.
Usemos el conjunto de datos iris y apliquemos el enfoque de bosque aleatorio. Necesitamos instalar caTools y randomForest para implementar el bosque aleatorio en R.
install.packages("caTools")
install.packages("randomForest")
Una vez que los paquetes están instalados, podemos cargarlos e iniciar el enfoque de bosque aleatorio. Ver ejemplo:
# Loading package
library(caTools)
library(randomForest)
# Split the data in train data and test data with ratio 0.8
split_data <- sample.split(iris, SplitRatio = 0.8)
split_data
train_data <- subset(iris, split == "TRUE")
test_data <- subset(iris, split == "FALSE")
# Fit the random Forest to the train dataset
set.seed(120) # Setting seed
classifier_Random_Forest = randomForest(x = train_data[-4],
y = train_data$Species,
ntree = 400)
classifier_Random_Forest
El código anterior divide los datos del iris con una proporción de 0,8 y luego crea los datos del tren y de la prueba; finalmente, aplica el enfoque de bosque aleatorio con 400 árboles. La salida es:
Call:
randomForest(x = train_data[-4], y = train_data$Species, ntree = 400)
Type of random forest: classification
Number of trees: 400
No. of variables tried at each split: 2
OOB estimate of error rate: 0%
Confusion matrix:
setosa versicolor virginica class.error
setosa 30 0 0 0
versicolor 0 30 0 0
virginica 0 0 30 0
Una vez que se ajusta el modelo de bosque aleatorio, podemos predecir el resultado del conjunto de pruebas, ver la matriz de confusión y trazar los gráficos del modelo. Vea el código a continuación.
# Predict the Test set result
y_pred = predict(classifier_RF, newdata = test_data[-4])
# The Confusion Matrix
conf_matrix = table(test_data[, 4], y_pred)
conf_matrix
# Plot the random forest model
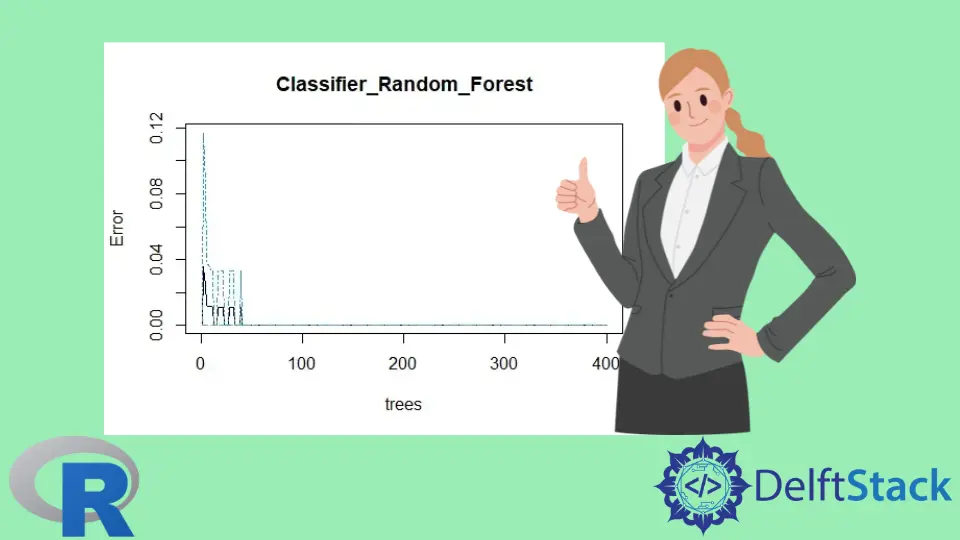
plot(classifier_Random_Forest)
# The importance plot
importance(classifier_Random_Forest)
# The Variable importance plot
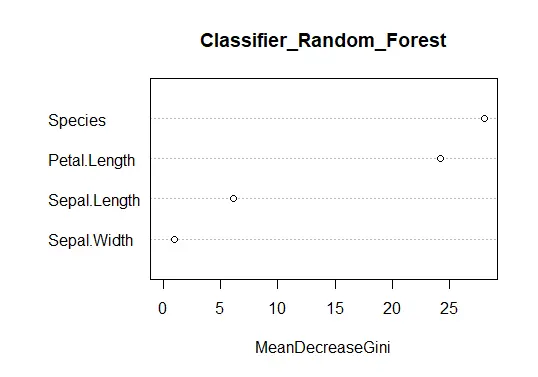
varImpPlot(classifier_Random_Forest)
El código anterior predice el resultado del conjunto de prueba y luego muestra la matriz de confusión. Finalmente, se muestra el gráfico del modelo de bosque aleatorio, el gráfico de importancia y el gráfico de importancia variable.
Ver salida:
> conf_matrix
y_pred
setosa versicolor virginica
0.1 1 0 0
0.2 10 0 0
0.3 3 0 0
0.4 4 0 0
0.5 1 0 0
0.6 1 0 0
1 0 2 0
1.1 0 1 0
1.2 0 1 0
1.3 0 5 0
1.4 0 3 0
1.5 0 6 1
1.6 0 1 1
1.7 0 1 0
1.8 0 2 4
1.9 0 0 3
2 0 0 3
2.1 0 0 1
2.3 0 0 4
2.4 0 0 1
La gráfica del modelo Random Forest:
La Importancia del modelo de bosque aleatorio:
MeanDecreaseGini
Sepal.Length 6.1736467
Sepal.Width 0.9664428
Petal.Length 24.1454822
Species 28.0489838
El gráfico de Importancia de la variable:

Sheeraz is a Doctorate fellow in Computer Science at Northwestern Polytechnical University, Xian, China. He has 7 years of Software Development experience in AI, Web, Database, and Desktop technologies. He writes tutorials in Java, PHP, Python, GoLang, R, etc., to help beginners learn the field of Computer Science.
LinkedIn Facebook