Unterschied zwischen Repository-Pattern und DAO in Java
- Datenzugriffsobjektmuster
- Repository-Muster
- Unterschied zwischen dem Datenzugriffsobjekt (DAO) und Repository-Mustern in Java
- Unterschied zwischen der DAO- und Repository-Pattern-Implementierung
Heute lernen wir das Data Access Object (DAO) und Repository-Muster kennen. Dieser Artikel informiert auch über die Unterschiede zwischen ihnen.
Datenzugriffsobjektmuster
Dieses Muster ist die Abstraktion der Datenpersistenz, die auch näher am zugrunde liegenden Speicher betrachtet wird, der hauptsächlich tabellenzentriert ist. Aus diesem Grund stimmen die Datenzugriffsobjekte (DAOs) meistens mit den Datenbanktabellen überein und ermöglichen die einfachste Methode zum Abrufen und Senden von Daten aus dem Speicher, während die hässlichen Abfragen verborgen werden.
Repository-Muster
Ein Repository-Muster ist ein Verfahren zum Abrufen gespeicherter Daten aus unserer Anwendung, das jeden Aspekt eines Datenspeichersystems verbirgt. Es folgt die Repository-Schnittstelle, mit der wir einen Benutzer anhand seines Benutzernamens suchen können.
interface UserRepository {
User findUserByUsername(Username name);
}
Dies kann eine oder mehrere Implementierungen basierend auf unserer Speichertechnologie haben – zum Beispiel MySQL, Amazon DynamoDB, Web Service, Oracle oder andere.
Wir können auch sagen, dass das Repository-Muster ein Entwurfsmuster ist, das die Datenquelle vom Rest einer Anwendung isoliert. Das Repository vermittelt zwischen den Datenquellen (z. B. Webdiensten und persistenten Modellen) und dem Rest einer Anwendung.
Es folgt die grafische Darstellung der Verwendung des Repository-Musters.
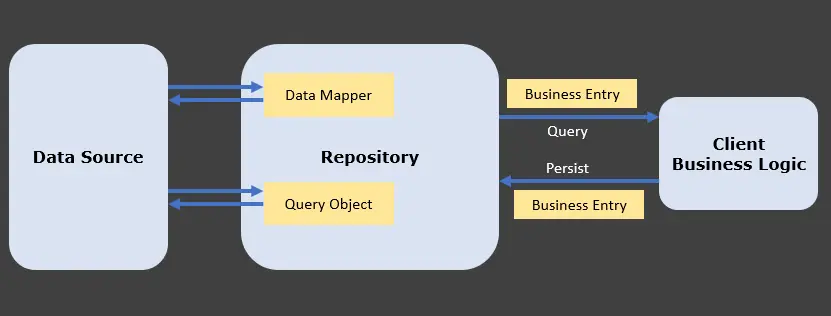
Sie verstehen richtig, dass das Repository dem Data Access Object (DAO) ähnelt, aber eine Abstraktion ist, die die gesamte Logik verbirgt, die zum Abrufen der Daten aus der Geschäftslogik verwendet wird.
Es verhält sich wie ein Wrapper um das Modell und ist für den Zugriff auf Daten aus einem persistenten Speicher verantwortlich. Der Vorteil der Verwendung eines Repositorys besteht darin, dass es die genauen Details darüber, wie unsere Inhalte gespeichert werden, von der Anwendung trennt, die es verwendet.
Dies ist zum Testen extrem wichtig, da wir Stub-Code schreiben können, der immer einen Benutzer zurückgibt, aber nicht auf die Datenbank zugreift. Es befreit uns von verschiedenen Problemen und lässt uns den schnellen Komponententest für unseren Anwendungscode schreiben, der nicht von den gespeicherten Daten abhängt.
Unterschied zwischen dem Datenzugriffsobjekt (DAO) und Repository-Mustern in Java
Der Hauptunterschied besteht darin, dass das Repository nur die Objekte zurückgibt, die für eine aufrufende Schicht verständlich sind. Meist wird das Repository von einer Business-Schicht verwendet und gibt somit die Business-Objekte aus.
Auf der anderen Seite gibt das Datenzugriffsobjekt die Daten zurück, die möglicherweise das gesamte Geschäftsobjekt sind oder nicht. Dies bedeutet, dass die Daten kein gültiges Geschäftskonzept darstellen.
Wenn unsere Geschäftsobjekte nur die Datenstrukturen sind, kann dies darauf hindeuten, dass wir das Modellierungsproblem haben. Es bedeutet schlechtes Design, während ein Repository mit zumindest richtig gekapselten Objekten sinnvoller ist.
Wenn wir die Datenstrukturen nur laden oder speichern, brauchen wir höchstwahrscheinlich kein Repository. Das Object Relational Mapping (ORM) reicht aus.
Ein Repository-Muster ist die beste Lösung, wenn wir es mit einem Geschäftsobjekt zu tun haben, das aus verschiedenen anderen Objekten besteht (einem Aggregat), und dieses spezielle Objekt erfordert, dass alle seine Teile konsistent sind (Aggregatstamm).
Dies liegt daran, dass vollständige Persistenzinformationen abstrahiert werden. Unsere Anwendung fragt nur nach einem Product, und das Repository gibt das als Ganzes zurück; es spielt keine Rolle, wie viele Abfragen/Tabellen benötigt werden, um ein Objekt wiederherzustellen.
Denken Sie daran, dass das Geschäftsobjekt keine Entität für Object Relational Mapping (ORM) ist. Es mag aus technischer Sicht sein, aber in Anbetracht des Designs modelliert einer die geschäftlichen Dinge und der andere die Persistenz.
Meistens besteht keine direkte Kompatibilität.
Hier sind einige Situationen, in denen wir die Verwendung eines Repository-Musters bevorzugen:
- Es wird in einem System verwendet, in dem wir viele schwere Abfragen haben.
- Wir verwenden Repository-Muster, um doppelte Abfragen zu vermeiden.
- Es wird zwischen dem Datenspeicher und den Domänen (Entität) verwendet.
- Es wird auch zum Suchen und Entfernen eines Elements unter Verwendung der Spezifikation der Entität verwendet, für die das Repository erstellt wird.
Lassen Sie uns nun diesen Unterschied anhand der Codeimplementierung verstehen.
Unterschied zwischen der DAO- und Repository-Pattern-Implementierung
Beginnen wir mit der Implementierung des Datenzugriffsobjektmusters.
Implementierung des Datenzugriffsobjektmusters
Hier benötigen wir drei Klassen, die unten aufgeführt sind:
- Eine grundlegende Domänenklasse
Employee - Die
EmployeeDAO-Schnittstelle, die einfache CRUD-Operationen für eineEmployee-Domäne bereitstellt - Eine
EmployeeDAOImplementation-Klasse, die dieEmployeeDAO-Schnittstelle implementiert
Beispielcode (Klasse Employee):
public class Employee {
private Long id;
private String employeeCode;
private String firstName;
private String email;
// write your getters/setters
}
Beispielcode (EmployeeDAO-Schnittstelle):
public interface EmployeeDAO {
void create(Employee employee);
Employee read(Long id);
void update(Employee employee);
void delete(String employeeCode);
}
Beispielcode (Klasse EmployeeDAOImplementation):
public class EmployeeDAOImplementation implements EmployeeDAO {
private final EntityManager entityManager;
@Override
public void create(Employee employee) {
entityManager.persist(employee);
}
@Override
public Employee read(long id) {
return entityManager.find(Employee.class, id);
}
// ... continue with remaining code
}
Wir verwenden die JPA EntityManager-Schnittstelle, um mit dem zugrunde liegenden Speicher zu kommunizieren. Geben Sie auch den Datenzugriffsmechanismus für die Domäne Employee an.
Repository-Pattern-Implementierung
Dieses Muster kapselt die Speicherung, das Suchverhalten und den Abruf und simuliert die Sammlung von Objekten. Wie DAO verbirgt es auch Abfragen und verarbeitet Daten, befindet sich jedoch auf einer höheren Ebene näher an der Geschäftslogik der Anwendung.
Ein Repository kann das DAO auch verwenden, um die Daten aus einer Datenbank abzurufen. Außerdem kann es das Domänenobjekt füllen oder Daten aus der Domäne vorbereiten und sie dann zur Persistenz mithilfe von DAO an das Speichersystem senden.
Hier benötigen wir folgende Klassen:
- Eine
EmployeeRepository-Schnittstelle - Eine
EmployeeRepositoryImplementation-Klasse
Beispielcode (Schnittstelle EmployeeRepository):
public interface EmployeeRepository {
Employee get(Long id);
void add(Employee employee);
void update(Employee employee);
void remove(Employee employee);
}
Beispielcode (Klasse EmployeeRepositoryImplementation):
public class EmployeeRepositoryImplementation implements EmployeeRepository {
private EmployeeDAOImplementation employeeDAOImplementation;
@Override
public Employee get(Long id) {
Employee employee = employeeDAOImplementation.read(id);
return employee;
}
@Override
public void add(Employee employee) {
employeeDAOImplementation.create(employee);
}
// ... continue with remaining code
}
Hier verwenden wir die EmployeeDAOImplementation, um Daten aus einer Datenbank abzurufen/zu senden. Wir können also sagen, dass die Implementierung von Repository und DAO ähnlich aussehen.
Dies liegt daran, dass die Klasse Employee die anämische Domäne ist und ein Repository nur eine weitere Schicht über der Datenzugriffsschicht (DAO) ist; Ein Repository ist jedoch der beste Weg, um den geschäftlichen Anwendungsfall zu implementieren. Im Vergleich dazu scheint das Datenzugriffsobjekt ein guter Kandidat für den Zugriff auf die Daten zu sein.
