填充 Pandas DataFrame 中的缺失值

有時,我們可能有一個缺失值的資料集。有很多方法可以使用某些方法來替換丟失的資料。
ffill()(前向填充)是替換 DataFrame 中缺失值的方法之一。此方法將 NaN 替換為先前的行或列值。
Pandas 中 ffill() 方法的語法
# Python 3.x
dataframe.ffill(axis, inplace, limit, downcast)
ffill() 方法採用四個可選引數:
axis指定從何處填充缺失值。值 0 表示行,1 表示列。inplace可以是 True 或 False。True 指定在當前 DataFrame 中進行更改,而 False 表示建立具有填充值的新 DataFrame 的單獨副本。limit指定要沿軸連續填充的最大缺失值數。downcast指定要為特定資料型別填充的值字典。
使用 Pandas 中的 ffill() 方法填充 DataFrame 中的缺失值
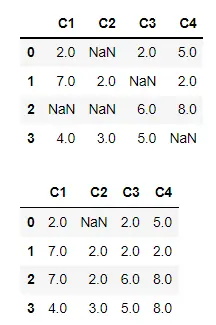
沿行軸填充缺失值
在下面的程式碼中,我們有一個缺失值用 None 或 NaN 表示的 DataFrame。我們已經顯示了實際的 DataFrame,然後將 ffill() 方法應用於該 DataFrame。
預設情況下,ffill() 方法會沿著行/索引軸替換缺失值。NaN 將替換為該單元格上一行的值。
第一行在輸出中仍然包含 NaN,因為沒有前一行。
示例程式碼:
# Python 3.x
import pandas as pd
df = pd.DataFrame(
{
"C1": [2, 7, None, 4],
"C2": [None, 2, None, 3],
"C3": [2, None, 6, 5],
"C4": [5, 2, 8, None],
}
)
display(df)
df2 = df.ffill()
display(df2)
輸出:
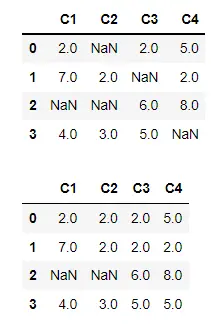
沿列軸填充缺失值
在這裡,我們將指定 axis=1。它將通過觀察相應單元格的前一列中的值來填充缺失值。
在輸出中,除了兩個值之外,所有值都被填充。因為我們沒有列 1 的前一列,所以該值仍然是 NaN。
第 2 列中的值是 NaN,因為前一列中對應的單元格也是 NaN。
示例程式碼:
# Python 3.x
import pandas as pd
df = pd.DataFrame(
{
"C1": [2, 7, None, 4],
"C2": [None, 2, None, 3],
"C3": [2, None, 6, 5],
"C4": [5, 2, 8, None],
}
)
display(df)
df2 = df.ffill(axis=1)
display(df2)
輸出:
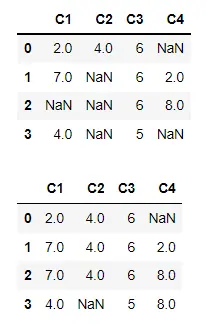
使用 limit 限制要填充的連續 NaN 的數量
我們可以使用 limit 引數來限制沿行或列軸填充的連續缺失值的數量。
在下面的程式碼中,我們有實際的 DataFrame,其中最後三行有連續的 NaN。如果我們指定 limit=2,則不能超過兩個連續的 NaN 可以沿行軸填充。
這就是為什麼最後一行中的 NaN 仍未填充的原因。
示例程式碼:
# Python 3.x
import pandas as pd
df = pd.DataFrame(
{
"C1": [2, 7, None, 4],
"C2": [4, None, None, None],
"C3": [6, 6, 6, 5],
"C4": [None, 2, 8, None],
}
)
display(df)
df2 = df.ffill(axis=0, limit=2)
display(df2)
輸出:
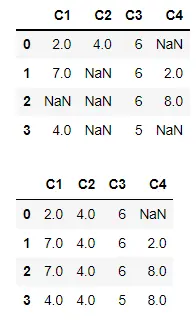
使用 inplace 填充原始 DataFrame 中的值
假設我們想要在原始 DataFrame 中進行更改,而不是在另一個 DataFrame 中複製具有填充值的 DataFrame。在這種情況下,我們可以使用值為 True 的 inplace 引數。
示例程式碼:
# Python 3.x
import pandas as pd
df = pd.DataFrame(
{
"C1": [2, 7, None, 4],
"C2": [4, None, None, None],
"C3": [6, 6, 6, 5],
"C4": [None, 2, 8, None],
}
)
display(df)
df.ffill(inplace=True)
display(df)
輸出:

I am Fariba Laiq from Pakistan. An android app developer, technical content writer, and coding instructor. Writing has always been one of my passions. I love to learn, implement and convey my knowledge to others.
LinkedIn