MongoDB의 조회 연산자에서 파이프라인 사용

이 튜토리얼은 MongoDB의 lookup 연산자에서 파이프라인을 사용하는 방법을 알려줍니다. 계속 진행하기 전에 MongoDB를 사용하는 동안 $lookup 연산자의 파이프라인 사용을 이해하려면 집계 파이프라인 및 $lookup 연산자에 대한 충분한 지식이 있어야 합니다.
이러한 개념을 이미 알고 있다면 이 자습서의 마지막 두 코드 예제로 빠르게 이동할 수 있습니다.
집계 파이프라인이란
데이터를 수집하고 계산된 결과를 반환하는 절차입니다. 이 프로세스는 서로 다른 문서에서 데이터를 수집하고 지정된 조건에 따라 그룹화하고 그룹화된 데이터에 대해 다양한 작업을 수행합니다.
예를 들어, 평균, 합계, 최대 및 최소. SQL 집계 함수와 같습니다.
MongoDB에서는 다음 세 가지 방법으로 집계를 사용할 수 있습니다.
-
집계 파이프라인 - 제공된 문서를 변환하는 다양한 단계를 포함합니다. 모든 단계는 일련의 문서를 수락하고 다음 단계로 더 전달되는 또 다른 결과 문서 세트를 생성하며 이 프로세스는 최종 단계까지 계속됩니다.
-
Map-reduce 함수 - 이 함수를 사용하여 결과를 대규모로 집계합니다.
map과reduce의 두 가지 기능이 있습니다.map방법은 모든 문서를 그룹화하는 반면reduce방법은 그룹화된 데이터에 대한 작업을 수행합니다. -
단일 목적 집계 - 집계 작업을 수행하는 데 사용되는 가장 간단한 집계 형식이지만 집계 파이프라인 방법에 비해 몇 가지 기능이 부족합니다. 이 유형의 집계를 사용하여 특정 문서 내에서 작업을 수행합니다. 예를 들어 특정 문서 내에서 고유한 값을 계산합니다.
또한 이 링크를 읽고 더 깊이 파고들어 집계 파이프라인을 알 수 있습니다.
MongoDB의 $lookup 연산자는 무엇입니까?
이 연산자는 동일한 데이터베이스 내에서 한 문서의 데이터를 다른 문서로 병합하기 위해 왼쪽 외부 조인을 수행하는 데 사용됩니다. 추가 처리를 위해 결합된 컬렉션에서 문서를 필터링합니다.
이 연산자를 사용하여 기존 문서에 필드를 추가할 수도 있습니다.
$lookup 연산자는 값(요소)이 결합된 컬렉션의 문서와 일치하는 새 배열 속성(필드)을 추가합니다. 그런 다음 이러한 변환된 문서는 다음 단계로 전달됩니다.
$lookup 연산자에는 프로젝트 요구 사항을 고려하여 사용할 수 있는 세 가지 구문이 있습니다. 이 튜토리얼은 Join conditions & Subqueries on the Joined Collection에 $lookup 구문을 사용합니다.
예제 코드로 연습하기 위해 데이터로 샘플 컬렉션을 준비하겠습니다.
예제 코드:
db.createCollection('collection1');
db.createCollection('collection2');
db.collection1.insertMany([
{"shopId": "001", "shopPosId": "001", "description": "description for 001"},
{"shopId": "002", "description": "description for 002"},
{"shopId": "003", "shopPosId": "003", "description": "description for 003"},
{"shopId": "004", "description": "description for 004"}
]);
db.collection2.insertMany([
{"shopId": "001", "shopPosId": "0078", "clientUid": "474192"},
{"shopId": "002", "shopPosId": "0012", "clientUid": "474193"},
{"shopId": "003", "shopPosId": "0034", "clientUid": "474194"},
{"shopId": "004", "shopPosId": "0056", "clientUid": "474195"}
]);
이제 다음 명령을 실행하여 각 컬렉션에 삽입된 문서를 볼 수 있습니다.
db.collection1.find();
db.collection2.find();
$lookup 연산자에서 파이프라인을 사용하여 MongoDB에서 조건 조인
$lookup 연산자에서 파이프라인을 사용하는 방법을 배우기 위해 collection1.shopId가 collection2.shopId와 같고 collection1에 shopPosId 필드가 포함되지 않은 두 컬렉션의 문서를 결합해 보겠습니다. .
두 조건을 모두 충족하는 두 컬렉션의 문서만 결합됩니다. 아래에 제공된 예제 코드를 참조하십시오.
예제 코드:
db.collection2.aggregate([
{
"$lookup": {
"from": "collection1",
"let": { "shopId": "$shopId" },
"pipeline": [{
"$match": {
"$and": [
{"$expr": {"$eq": ['$shopId', '$$shopId'] }},
{ "shopPosId": { "$exists": false } }
]
}
}],
"as": "shopDescription"
}
}
]).pretty();
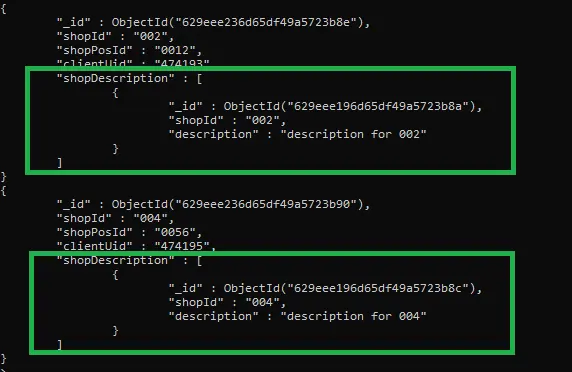
출력:
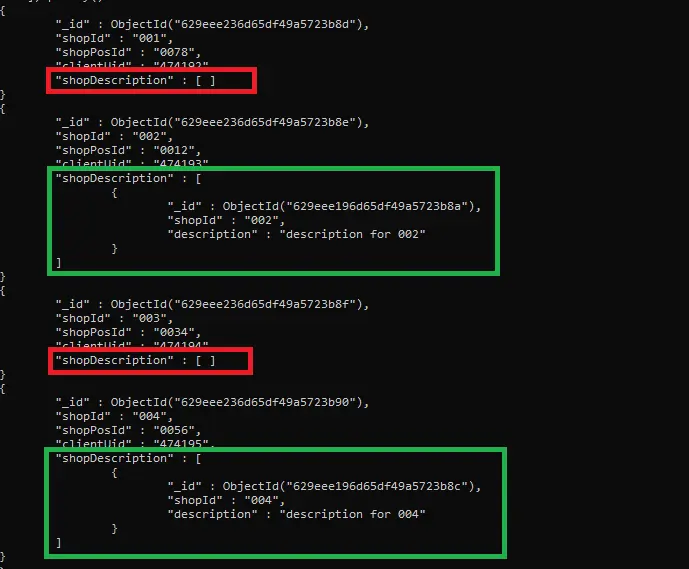
위에 주어진 출력을 주의 깊게 관찰했습니까? 파이프라인의 두 조건을 모두 충족하는 두 컬렉션의 문서만 결합됩니다(collection1.shopId는 collection2.shopId와 같고 collection1에는 shopPosId 필드가 포함되지 않음).
또한 이러한 조건과 일치하지 않는 문서에는 shopDescription이라는 빈 배열이 있습니다(위 결과의 빨간색 상자 참조). 비어 있지 않은 shopDescription 배열을 포함하는 결과 문서만 표시할 수 있습니다(다음 쿼리 참조).
예제 코드:
db.collection2.aggregate([
{
"$lookup": {
"from": "collection1",
"let": { "shopId": "$shopId" },
"pipeline": [{
"$match": {
"$and": [
{"$expr": {"$eq": ['$shopId', '$$shopId'] }},
{ "shopPosId": { "$exists": false } }
]
}
}],
"as": "shopDescription"
}
},
{
"$match":{
"shopDescription": { $exists: true, $not: {$size: 0} }
}
}
]).pretty();
출력: