Méthode Scipy scipy.optimize.curve_fit
-
Syntaxe de
scipy.optimize.curve_fit(): -
Exemples de codes : méthode
scipy.optimize.curve_fit()pour ajuster une ligne droite à nos données (expression du modèle linéaire) -
Exemple de code :
scipy.optimize.curve_fit()Méthode pour ajuster la courbe exponentielle à nos données (expression de modèle exponentiel)
La fonction Python Scipy scipy.optimize.curve_fit() est utilisée pour trouver les paramètres les mieux ajustés à l’aide d’un ajustement des moindres carrés. La méthode curve_fit ajuste notre modèle aux données.
L’ajustement de la courbe est essentiel pour trouver l’ensemble optimal de paramètres pour la fonction définie qui correspond le mieux à l’ensemble d’observations fourni.
Syntaxe de scipy.optimize.curve_fit() :
scipy.optimize.curve_fit(f, xdata, ydata, sigma=None, p0=None)
Paramètres
f |
C’est la fonction modèle. Prend la variable indépendante comme premier argument et les paramètres à ajuster comme arguments restants séparés. |
xdata |
Comme un tableau. Variable indépendante ou entrée de la fonction. |
ydata |
Comme un tableau. Variable dépendante. La sortie de la fonction.. |
sigma |
Valeur facultative. Il s’agit des incertitudes estimées dans les données. |
p0 |
Conjecture initiale pour les paramètres. L’ajustement de la courbe doit savoir où il doit commencer la chasse, quelles sont les valeurs raisonnables pour les paramètres. |
Retourner
Il retourne deux valeurs :
popt: semblable à un tableau. Il contient les valeurs optimales pour la fonction du modèle. Contient en interne les résultats d’ajustement pour lapenteet les résultats de l’ajustement pour l’intercept.p-cov: Covariance, qui dénote des incertitudes sur le résultat de l’ajustement.
Exemples de codes : méthode scipy.optimize.curve_fit() pour ajuster une ligne droite à nos données (expression du modèle linéaire)
import numpy as np
import matplotlib.pyplot as plt
import scipy
from scipy import optimize
def function(x, a, b):
return a * x + b
x = np.linspace(start=-50, stop=10, num=40)
y = function(x, 6, 2)
np.random.seed(6)
noise = 20 * np.random.normal(size=y.size)
y = y + noise
popt, cov = scipy.optimize.curve_fit(function, x, y)
a, b = popt
x_new_value = np.arange(min(x), 30, 5)
y_new_value = function(x_new_value, a, b)
plt.scatter(x, y, color="green")
plt.plot(x_new_value, y_new_value, color="red")
plt.xlabel("X")
plt.ylabel("Y")
print("Estimated value of a : " + str(a))
print("Estimated value of b : " + str(b))
plt.show()
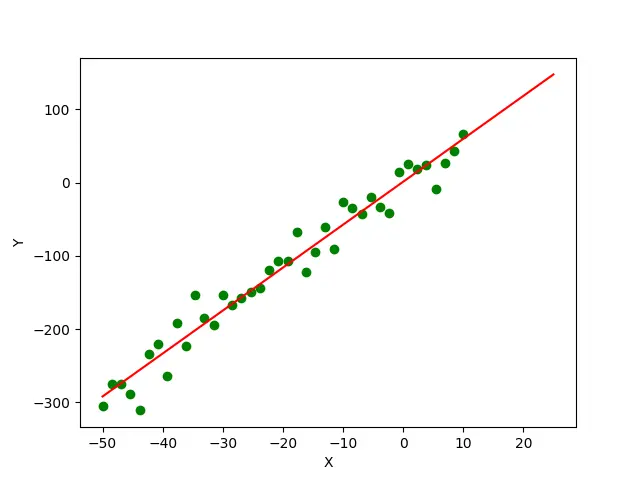
Production :
Estimated value of a : 5.859050240780936
Estimated value of b : 1.172416121927438
Dans cet exemple, nous générons d’abord un jeu de données avec 40 points en utilisant l’équation y = 6*x+2. Ensuite, nous ajoutons du bruit gaussien aux valeurs y du jeu de données pour le rendre plus réaliste. Nous estimons maintenant les paramètres a et b de l’équation sous-jacente y=a*x+b, qui génère le jeu de données à l’aide de la méthode scipy.optimize.curve_fit(). Les points verts du tracé représentent les points de données réels du jeu de données et la ligne rouge représente la courbe ajustée au jeu de données à l’aide de la méthode scipy.optimize.curve_fit().
Enfin, nous pouvons voir que les valeurs de a et b estimées à l’aide de la méthode scipy.optimize.curve_fit() sont respectivement 5.859 et 1.172, ce qui est assez proche des valeurs réelles 6 et 2.
Exemple de code : scipy.optimize.curve_fit() Méthode pour ajuster la courbe exponentielle à nos données (expression de modèle exponentiel)
import numpy as np
import matplotlib.pyplot as plt
import scipy
from scipy import optimize
def function(x, a, b):
return a * np.exp(b * x)
x = np.linspace(10, 30, 40)
y = function(x, 0.5, 0.3)
print(y)
noise = 100 * np.random.normal(size=y.size)
y = y + noise
print(y)
popt, cov = scipy.optimize.curve_fit(function, x, y)
a, b = popt
x_new_value = np.arange(min(x), max(x), 1)
y_new_value = function(x_new_value, a, b)
plt.scatter(x, y, color="green")
plt.plot(x_new_value, y_new_value, color="red")
plt.xlabel("X")
plt.ylabel("Y")
print("Estimated value of a : " + str(a))
print("Estimated value of b : " + str(b))
plt.show()
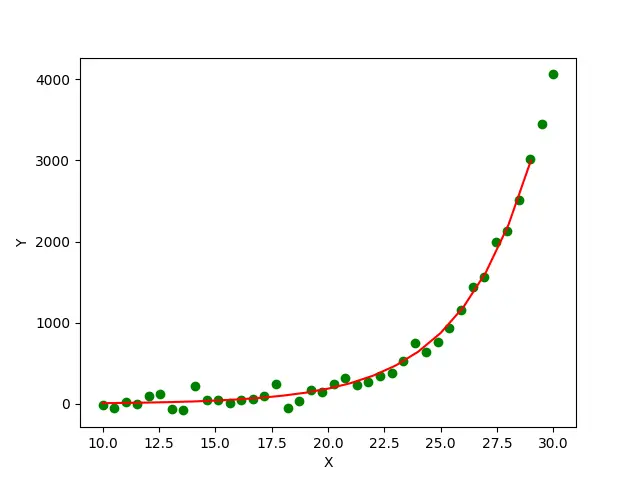
Production :
Estimated value of a : 0.5109620054206334
Estimated value of b : 0.2997005016319089
Dans cet exemple, nous générons d’abord un jeu de données avec 40 points en utilisant l’équation y = 0.5*x^0.3. Ensuite, nous ajoutons du bruit gaussien aux valeurs y du jeu de données pour le rendre plus réaliste. Nous estimons maintenant les paramètres a et b de l’équation sous-jacente y = a*x^b qui génère le jeu de données à l’aide de la méthode scipy.optimize.curve_fit(). Les points verts du tracé représentent les points de données réels du jeu de données et la ligne rouge représente la courbe ajustée au jeu de données à l’aide de la méthode scipy.optimize.curve_fit().
Enfin, nous pouvons voir que les valeurs de a et b estimées à l’aide de la méthode scipy.optimize.curve_fit() sont respectivement 0.5109 et 0.299, ce qui est assez proche des valeurs réelles 0.5 et 0.3.
De cette manière, nous pouvons déterminer l’équation sous-jacente de points de données donnés à l’aide de la méthode scipy.optimize.curve_fit().

Suraj Joshi is a backend software engineer at Matrice.ai.
LinkedIn