Escritura de consultas que no distinguen entre mayúsculas y minúsculas en PostgreSQL
-
Usar
COINCIDENCIA DE PATRONESen PostgreSQL -
Use la función
INFERIORpara hacer que los casos sean similares mientras busca en PostgreSQL -
el uso de
CONVERSIÓN DE CASOen PostgreSQL -
Use
CITEXTal crear una tabla para realizar coincidenciasINSENSIBLES A CASEen PostgreSQL

Al escribir una consulta en nuestro DBMS, a menudo notamos que algunos caracteres deben estar en mayúsculas o minúsculas según las condiciones requeridas para satisfacer una cláusula o sintaxis. Como resultado, se debe encontrar un método para completar consultas y evitar errores de sintaxis comunes, independientemente de las circunstancias.
Este artículo discutirá cómo escribir consultas que no distinguen entre mayúsculas y minúsculas en PostgreSQL.
Usar COINCIDENCIA DE PATRONES en PostgreSQL
Una de las formas de optimizar las consultas en PostgreSQL donde intentamos encontrar algo en nuestra base de datos y tenemos que proporcionarle una cadena específica para que coincida con los objetos contenidos, es posible que necesitemos usar los mismos caracteres que usamos para eso. objeto durante la búsqueda.
Esto podría crear problemas si olvidamos la sintaxis exacta del nombre del objeto cuando se definió anteriormente.
Aquí podemos usar algo tan simple como COINCIDENCIA DE PATRONES. Tenemos una tabla ANIMAL con ID, EDAD y TIPO.
La tabla ya contiene datos de la siguiente manera:
ID AGE TYPE
1 2 12 "Horse"
2 1 3 "Cat"
3 3 4 "Kitten"
Podemos utilizar la consulta a continuación para encontrar todos los ANIMALES con el tipo GATITO.
Consulta:
select * from ANIMAL where type = 'Kitten';
Producción:

Sin embargo, si escribimos la siguiente consulta:
select * from ANIMAL where type = 'kitten';
Entonces no obtendremos nada en nuestro resultado, y esto sucede porque el carácter 'k' no es igual a 'K'. Para resolver esto, podemos usar el operador ILIKE para hacer que la coincidencia no distinga entre mayúsculas y minúsculas.
Consulta:
select * from ANIMAL where type ILIKE 'kitten';
Esta consulta devuelve todos los animales que son del tipo GATITO. Una modificación a este código puede ser el operador de signo que puede usarse alternativamente con ILIKE.
Consulta:
select * from ANIMAL where type ~~* 'kitten';
Otro método que podemos usar es el operador LIKE o SIMILAR TO, pero solo se pueden usar si recordamos las partes del nombre con sus mayúsculas y minúsculas correctas.
Para buscar GATITO, por ejemplo, si recordamos que nuestro nombre tenía ITTEN pequeño y K era o bien PEQUEÑO o GRANDE, podemos escribir algo como lo siguiente para consultar el resultado.
Consulta:
select * from ANIMAL where type similar to '%itten';
Esta no es una buena alternativa y debe usarse si el usuario tiene alguna idea de la convención de nomenclatura utilizada al crear objetos. ILIKE proporciona un mejor manejo de mayúsculas y minúsculas al hacer coincidir los patrones con la cadena proporcionada.
Use la función INFERIOR para hacer que los casos sean similares mientras busca en PostgreSQL
Una forma muy eficiente de hacer coincidir un patrón con una cadena puede ser hacer que los caracteres de ambos sean similares. Ya sea convirtiendo todos los caracteres a INFERIOR o SUPERIOR y luego combinándolos respectivamente.
PostgreSQL nos proporciona una función LOWER() así como UPPER() para verificar.
Consulta:
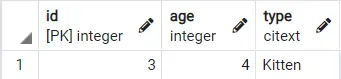
select * from ANIMAL where lower(type) = lower('kitten')
o
select * from ANIMAL where lower(type) = lower('kitten')
Producción:
De manera similar, podemos usar INITCAP para poner en mayúsculas solo la letra inicial de nuestro patrón y cadena y el resto en minúsculas para hacer coincidir y verificar.
Consulta:
select * from ANIMAL where initcap(type) = initcap('kitten')
el uso de CONVERSIÓN DE CASO en PostgreSQL
INDEXES ON EXPRESSIONS en PostgreSQL acelera la consulta de resultados de una tabla grande. En lugar de llamar a la misma consulta repetidamente en una tabla, lo que lleva más tiempo, podemos indexarla y luego usarla cuando se consulte.
Recuerde que las CONVERSIONES DE CASOS pueden invalidar los ÍNDICES preexistentes, ya que es posible que deban actualizarse nuevamente. Podemos escribir las siguientes consultas para crear un índice para este CASO COINCIDENTE.
Consulta:
create index lower_col on ANIMAL (lower(type));
o
create index upper_col on ANIMAL (upper(type));
Y de manera similar para INITCAP también. Estos ÍNDICES pueden incluso usarse para imponer restricciones para la INSERCIÓN DE FILA, donde si se INSERTA un conjunto de datos con un CASO diferente, puede invalidarse en la duplicación.
Para acelerar las consultas LIKE e ILIKE, podemos utilizar los índices GIN o GIST con una PG_TRGM_EXTENSION.
Use CITEXT al crear una tabla para realizar coincidencias INSENSIBLES A CASE en PostgreSQL
Otra alternativa a la coincidencia común en PostgreSQL es usar la cláusula CITEXT. Internamente llama a LOWER() cuando compara valores en lugar de que el usuario ponga LOWER() cada vez que intenta hacer coincidir una cadena con un patrón.
Vamos a crear la tabla ANIMAL con la columna TYPE como CITEXT.
create extension CITEXT; --creating the extension first
create table ANIMAL(
id INT PRIMARY KEY,
age INT,
TYPE CITEXT
)
Luego, INSERTAR los mismos valores de la tabla anterior. Ahora, use la siguiente consulta para devolver un resultado.
select * from ANIMAL where type = 'kitten';
Podemos ver que usar CITEXT en nuestras columnas es económico, más eficiente y más rápido que muchas de las soluciones dadas anteriormente. CITEXT depende de la configuración LC_CTYPE de la base de datos, y esto se puede modificar según sus necesidades.
Aquí hay algunos puntos importantes sobre las CONVERSIONES DE CASOS antes de emparejar.
- No se pueden convertir casos a diferentes idiomas (excepto inglés).
- Las funciones
LOWER()yUPPER()son más lentas debido a que no están indexadas.
Estas son todas las diferentes formas de comparar cadenas con patrones en PostgreSQL.

Hello, I am Bilal, a research enthusiast who tends to break and make code from scratch. I dwell deep into the latest issues faced by the developer community and provide answers and different solutions. Apart from that, I am just another normal developer with a laptop, a mug of coffee, some biscuits and a thick spectacle!
GitHub